Contextual and Sequential User Embeddings for Music Recommendation

Using a music listening dataset from Spotify, we observe that consumption from the recent past and session-level contextual variables (such as the time of the day or the type of device used) are predictive of the tracks a user will stream. Driven by these findings, we propose CoSeRNN, a neural network architecture that models users’ preferences as a sequence of embeddings, one for each session. CoSeRNN predicts, at the beginning of a session, a preference vector, based on past consumption history and current context. This preference vector is then used in downstream tasks to generate contextually relevant just-in-time recommendations efficiently, by using approximate nearest-neighbour search algorithms. We evaluate CoSeRNN on session and track ranking tasks, and find that it outperforms the current state of the art and that sequential and contextual information are both crucial.
Problem formulation
Compared to domains such as recommending books, movies or clothes, music recommender systems face distinctive challenges. Tracks are short, and therefore often consumed together with other tracks. We refer to such a set of tracks listened to in short succession as a session. A given session often contains tracks from the user's recent consumption history, suggesting that the sequence of sessions captures essential information about users' changing preferences. Additionally, the relevance of tracks is highly contextual, and preferences depend, among others, on the time of the day.
This research seeks to embrace these distinctive characteristics to produce a better, more accurate model of user preferences. We focus on the following problem: for a given user, we are interested in predicting, at the beginning of a session, which tracks the user will listen to during the session. We assume that we have access to the user's past consumption and to information about the current context. This formulation of the problem enables generating recommendations that are not only matching the user's global tastes, but are also tailored to the specific context and situation they currently find themselves in.
Through Spotify, users have on-demand access to millions of music tracks. We consider the listening history of a two-month sample of 200,000 users. We group listening history into sessions, where we define a session as the set of music tracks consumed in a given time interval, such that two sessions are separated by at least 20 minutes of inactivity. We restricted our sample to users with an average of 220 sessions during the two-month period, where each session consists of 10 tracks on average.
We embed tracks in a latent semantic space using a word2vec bag-of-word model. The similarity between two tracks is then computed by using the cosine similarity between their embeddings. We represent a session as an average of the embedding of the tracks it contains.
Music consumption and context
We first investigate if diversity in music consumption depends on context. We collect all tracks appearing in each specific context, and compute the pairwise cosine similarities between tracks within each context. The figure below illustrates the distributions of pairwise similarities by using boxplots. For the time context, we see that early morning and night have significantly larger variability compared to afternoon and evening.
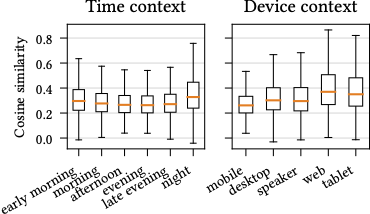
We observe a similar trend for the device context for all non-mobile contexts compared to mobile. What early morning, night and non-mobile device contexts have in common is that they represent a small fraction of all sessions. This suggests that users have largely different needs in these minority contexts, and as such the user embedding needs to incorporate context in order to reliably estimate user needs.
Session Similarity and Context
We next analyse if, for a given user, their sessions within the same context are more similar across different contexts. For each user and each session (the source), we find the nearest session (the target) among all the user’s other sessions, and store both the source’s and the target’s contexts. We then aggregate all the pairs and compute the empirical distribution of the target’s context type, conditioned on the source’s context type. The figure below displays the result in the form of heatmaps.
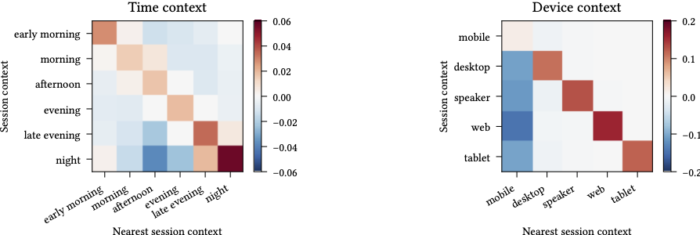
The positive diagonal tells us that sessions sharing the same context are indeed more similar than sessions sampled at random. Additionally, for time contexts, those occurring close to each other (e.g., night and evening) also often have small positive values, indicating that sessions even from consequent contexts are more similar than random sessions. This analysis highlights that sessions with the same context do share some similarities, which can be exploited to learn better performing contextual user embeddings.
Contextual Preferences and Skip Rate
Finally, we consider the influence of a better match between user and session embeddings (i.e., higher cosine similarity) on user satisfaction. As a proxy for satisfaction, we measure the skip rate, i.e., the percentage of skipped tracks within a session. We define the user embedding as an average of the embedding of all their previous sessions. For each session, we record the cosine similarity between the user embedding and the current session’s embedding, as well as the skip rate of the session. The figure below shows the Pearson correlation coefficient and regression slope between the skip rate and user-session cosine similarity, as a function of the minimum skip rate.
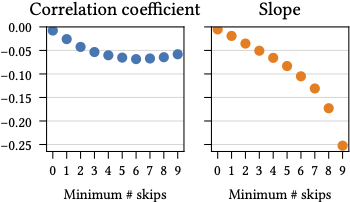
Both the correlation coefficient and regression slope are negative. This means that, as users skip more often, the user-session similarity decreases. Additionally, both the correlation coefficient and regression slope generally decrease the larger the minimum number of skips is. We expect that, if we were able to anticipate these “unusual” sessions (i.e., sessions that deviate significantly from a users’ average preference), we might be able to improve user satisfaction. Sequence and context-aware models enable us to achieve that goal.
Contextual and sequential model with recurrent network
Our exploratory analyses support the idea of learning sequence and context-aware models of user preferences. We introduce CoSeRNN (Contextual and Sequential Recurrent Neural Network), a user-embedding model that captures contextual and sequential preferences at the session level.
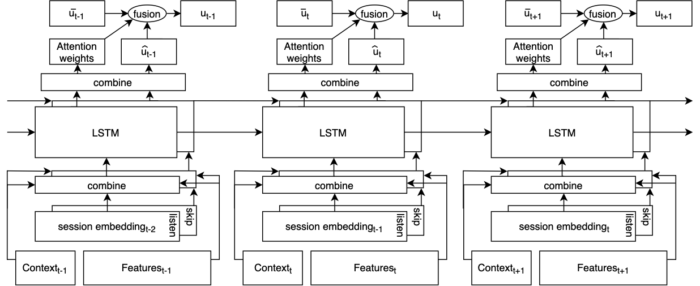
Our starting point is a vector-space embedding of tracks, where two tracks are close in space if they are likely to be listened to successively. Given this space, CoSeRNN models user preferences as a sequence of context-dependent embeddings (points in the track space), one for each session. At its core, it is a variant of a recurrent neural network that takes as input, for each session, the current session context and a representation of the user's past consumption. Given these, the model is trained to output an embedding that maximizes the cosine similarity to the tracks played during the session. We find that the most effective way to produce this embedding is to fuse a long-term, context-independent vector (intuitively capturing a user's average tastes) with a sequence and context-dependent offset (capturing current and context-specific preferences). An overview of the CoSeRNN model architecture is shown below.
Results
We evaluate our approach experimentally against multiple competing baselines on
a session ranking task, where the goal is to discriminate between the current session and previous ones, and
a track ranking task, where the goal is to predict which tracks a user will listen to in the current session.
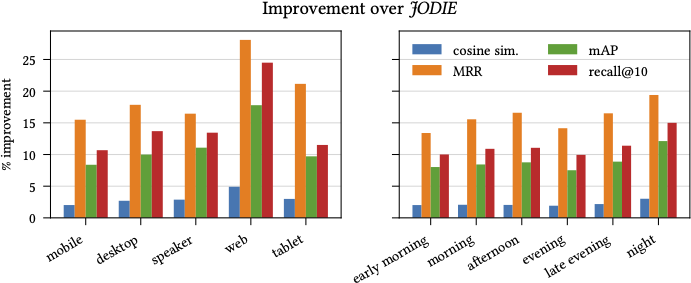
Our approach performs significantly better than competing approaches. We observe gains upwards of 10% on all ranking metrics we consider (see the paper for full detail). To answer the question “does the performance vary across contexts?”, we plot the relative improvement of CoSeRNN over the state-of-the-art approach, as shown in the figure below. Generally, the improvements are consistent across all contexts. Interestingly, some of the contexts that occur infrequently see a comparatively larger relative improvement, such as for the web or, to a smaller extent, night contexts.
We focus on the empirical performance of CoSeRNN and seek to understand how different choices affect the model, which we ablate in two different ways: 1) by varying the features given as input to the model, and 2) by processing played and skipped tracks in different ways.
We saw that the current session context is associated with the biggest increase in cosine similarity, which is to be expected as context is highly indicative of the content in a session. In addition, information about the previous session significantly helps improve performance, particularly on the track ranking task. If, in addition to knowing user devices and the time of the day, we know which stream source they intend to stream from, our model predictive performance increases substantially.
Separating played tracks from skipped tracks was shown to be clearly beneficial to model performance. We saw that considering skipped tracks in addition to played tracks did bring some performance benefits. Even though the performance benefit is small, this does highlight the dissimilarities between a user skipped and listened tracks, and it helps to improve the model capabilities of understanding a user's music preferences. Finally, considering the union of played and skipped tracks in addition to the two partitions is unnecessary and does not improve performance.
Some words on scalability
Setting predictive performance aside, we believe that our design choices also highlight an interesting point in the recommender systems solution space. Broadly speaking, our method falls within the realm of representation learning, which postulates that low-dimensional embeddings provide an effective way to model users and items. Whereas most of the work in this area has been focused on jointly learning user and item embeddings, we choose a different path, and instead take advantage of an existing track embedding space. By decoupling track and user embeddings, and learning the latter based on the former, we ensure interoperability with other models seeking to address problems that are distinct from contextual or sequential recommendations. In addition, our model does not seek to directly predict the individual tracks inside a session; instead, it generates a session-level user embedding, and relies on the assumption that tracks within the session lie inside a small region of the space. Relevant tracks can then be found efficiently using approximate nearest-neighbor search. This choice enables our method to scale to millions of tracks effortlessly.
Conclusions
This work considers the task of learning contextual and sequential user embeddings suited for music recommendation at the beginning of a session. Our exploratory analyses show that most users experience a diversity of contexts, that sessions belonging to rarely occurring contexts vary the most, and that sessions with the same context have more similar content. Driven by these findings, we present CoSeRNN, a recurrent neural network embedding model that learns the sequential listening behaviour of users, and adapts it to the current context. CoSeRNN outperforms baseline and state-of-the-art embedding-based approaches by upwards of 10% in session and track recommendation tasks. Finally, the approach taken by CoSeRNN enables efficiently generating recommendations by using fast approximate nearest-neighbour searches.
For further information, please refer to our paper: Contextual and Sequential User Embeddings for Large-Scale Music Recommendation Casper Hansen, Christian Hansen, Lucas Maystre, Rishabh Mehrotra, Brian Brost, Federico Tomasi and Mounia Lalmas RecSys 2020
SHARE THIS ARTICLE
