Improving Retrievability in Search with Query Generation
Allowing users to discover new entities such as books, music, and movies is an important goal for online platforms. This can be achieved for example by recommending entities that the user has not yet interacted with. Another way users can find new entities is by exploring the catalog with the search system. However, the popularity of an entity has a strong influence on which entities are surfaced by the search system, especially if a machine-learned model for retrieval was trained based on user interactions. If only a few entities are shown for the majority of the queries we say that the search system has a high retrievability bias.If this inequality is too strong, a number of entities that could be relevant for different information needs will never be surfaced.
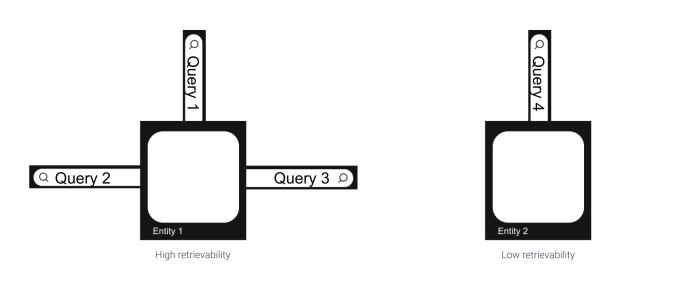
Retrievability means how accessible a document is via the search system. The track on the left has more retrievability than the right one as there are three “roads ” (queries) that lead to it, while the right track has only one. The number of times each query is issued is also taken into account to calculate the entities’ retrievability.
Besides the training data typically used to train such models, another factor that influences the retrievability of search systems is the distribution of the queries’ intents. Most users have a narrow underlying intent and just want to find the specific entity they have in mind. Users with broad intents on the other hand have an exploratory mindset and are willing to discover new entities when interacting with the search system. The amount of broad intent queries is small compared to narrow intent queries, which leads to a lot of search interactions with popular entities.
In order to mitigate such problems, we propose an approach to generate synthetic queries. For dealing with the bias in the training data, we can generate queries for every entity in the catalog, and use that as training data for the retrieval model. For dealing with the distribution of narrow and broad queries, we can generate broad query suggestions in order to influence user behavior.
Generating queries to mitigate retrievability bias
We introduce a model that for a given entity and the desired intent (narrow or broad), it generates a synthetic query for the chosen intent: CtrlQGen. The proposed model uses the metadata information available for the entity and learns how to generate queries based on that. Our model has three components: (1) serialization, which turns entities into a string representation, (2) weak labeling, which generates training data without access to ground-truth data and (3) intent-aware generation, which learns how to generate queries controlling for the intent. CtrlQGen can leverage any encoder-decoder pre-trained language model, e.g.T5, to implement component (3).
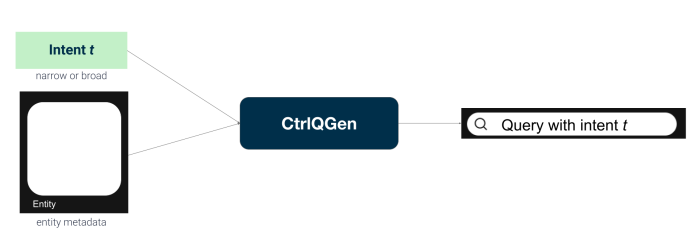
The proposed method generates a query for an entity controlling the underlying intent. For example, given the book “The Lord of the Rings” an example of a narrow query is “lord of the rings” and of a broad query is “fantasy book”.
In our experiments, we test the two main hypotheses regarding we discussed in the introduction to reduce the retrievability bias:
[H1] Training dense retrieval models with queries generated by CtrlQGen will lead to less retrievability bias compared to training with real queries and their respective clicked entities.
[H2] Suggesting broad queries using CtrlQGen will lead to less retrievability bias compared to the existing set of queries.
Results
Our experimental results on three different sample datasets—of music tracks and podcast episodes from Spotify, and a public book dataset—show thatindeed a transformer-based bi-encoder model trained on queries from the logs has a higher retrievability bias than a model trained on synthetic queries, which is positive evidence for [H1]. This is shown with an anecdotal example below, where we encode the representations of entities (pink color) and queries (grey color) learned by the bi-encoder models into a two-dimensional space. We see that the entities are better distributed with the queries generated by our model.
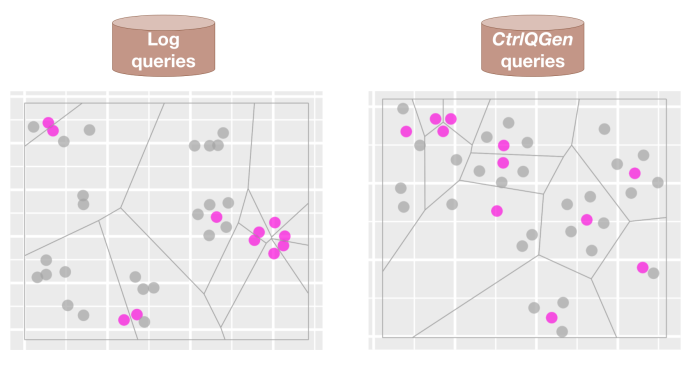
The left bi-encoder model trained on log queries and clicked entities surfaces the same four entities for most queries while six entities are never retrieved as the most similar entity. The right bi-encoder model trained with the generated queries by CtrlQGen distributes the queries better, i.e. has less retrievability bias.
We also show in our experiments that applying CtrlQGen for generating broad query suggestions can reduce the retrievability bias of the system by up to 9% percent, showing positive evidence for our second hypothesis [H2]. The framework for generating query suggestions using CtrlQGen is as follows: given the initial query issued by the user, for each entity in the ranked list for this query we apply CtrlQGen to generate broad queries. This way if a user is searching for something specific, we also suggest broader related content to explore via query suggestions.
Conclusion
Some content, e.g. tracks, podcasts, etc, is retrieved via many queries, while others get little to no exposure from search interactions. In this work, we show how to mitigate this retrievability bias with a query generation system that controls for the underlying intent of the query. We use the queries generated by the proposed CtrlQGen to either (I) train dense retrieval models or (II) as query suggestions. We believe that improving the capabilities of search systems to promote discoveries is an important direction of research for online media platforms.
For more information, please refer to our paper: Improving Content Retrievability in Search with Controllable Query Generation Gustavo Penha, Enrico Palumbo, Maryam Aziz, Alice Wang, and Hugues Bouchard TheWebConf 2023
SHARE THIS ARTICLE
