Audio-based Machine Learning Model for Podcast Language Identification
TL; DR
Existing spoken Language Identification (SLI) solutions focus on detecting languages from short audio clips. Podcast audio, on the other hand, poses peculiar challenges to SLI due to its heterogeneous nature, such as varied duration, diverse format and style, complex turn-taking with multiple speakers, and potential existence of the code-switching phenomenon. To address the challenge of podcast SLI, we developed a two-step ML system that can effectively identify language(s) from complex long audio and efficiently scale up. We evaluated the model on podcast audio and showed that it achieves strong performance results on the test set with an average F1 score of 91.23%. In addition, at inference time, the model can analyze and predict language for an 1-hour-long audio within less than 3 minutes.
Spoken Language Identification (SLI)
Spoken Language Identification (SLI) tackles the problem of identifying languages spoken from audio input, and thus it is crucial to the success of multilingual speech processing tasks, such as Automatic Speech Recognition (ASR) and speech translation. For example, when using the external Google Cloud's multilingual Speech-to-Text service, users are asked to specify at most four transcription languages, which preconditions a prior knowledge about the input language and thus imposes a dependency on human annotation or accurate metadata.
Existing SLI approaches and datasets, however, focus on tackling short-form, single-speaker audio that is shorter in duration and simpler in structure, and thus not suited for direct application to long-form audio like podcast due to drastic data shift. For example, current state-of-the-art SLI systems focus on tackling audio clips that are a few seconds long, while well-known SLI datasets vary from a few seconds to a few minutes in length.
Speaker Embeddings as Feature Input
Motivated by the observation that speaker embeddings — neural network generated vectors that embody the uniqueness of a person's voice characteristics — also capture important information relevant to the identification of languages, we set off by experimenting with the VGGVox speaker embeddings. VGGVox speaker embeddings are generated using the well-known state-of-the-art speaker identification and verification VGGVox model, which has been trained over a large set of diverse languages and dialects readily available from the VoxCelebb dataset. We investigated whether VGGVox speaker embeddings can serve as effective feature input for long-form audio SLI.
We randomly sampled 100 episodes for each of the five selected languages (English, Spanish, Portuguese, French, and Japanese) and extracted an average VGGVox speaker embedding for each episode. We then used T-SNE to visualize the average embeddings in a 2D space as shown in Figure 1:
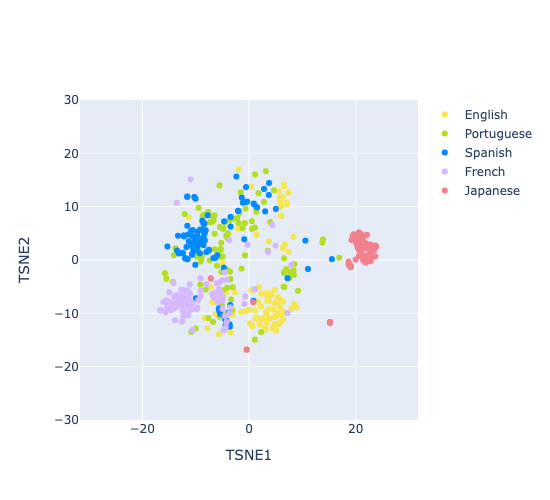
Figure 1. T-SNE plot of VGGVox speaker embeddings extracted from podcasts of 5 languages
Spanish, Portuguese, and French form their own cluster as they all belong to the Romance language family, while Spanish and Portuguese are more overlapped with each other due to high lexical similarity. English as a Germanic language forms its own cluster in the plot, though it is positioned quite close to the Romance language cluster due to the fact that English has Latin influences: a significant portion of the English vocabulary comes from Romance and Latinate sources. Japanese forms its own cluster and it is more separated from the other two clusters, as most words in Japanese do not derive from a Latin origin.
Overall, the T-SNE plot highlights the language distinctiveness of VGGVox speaker embeddings, proving its effectiveness as feature input for long-form audio SLI.
System Architecture and Training
Motivated by using VGGVox speaker embeddings as input for long-form audio SLI, we trained a two-step SLI system (as illustrated in Figure 2) on podcast audio. The SLI system consists of two main steps: (1) speaker embedding generation using unsupervised speaker diarization and (2) language prediction via a feedforward neural network (FNN).
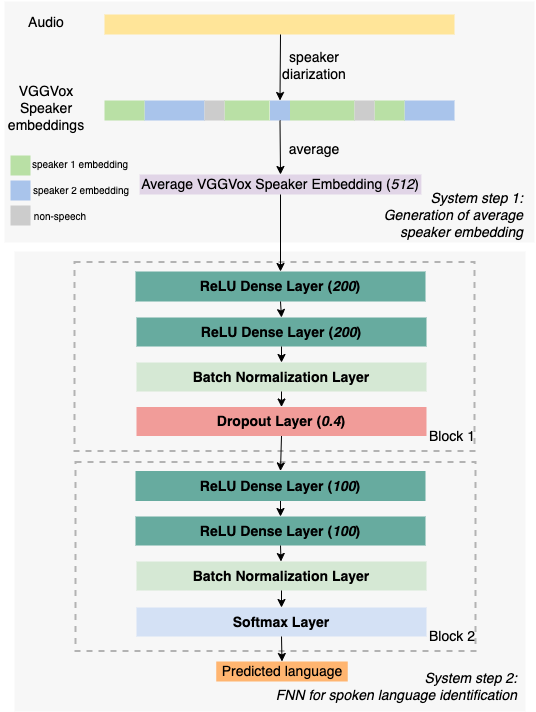
Figure 2. Two-step ML SLI system
We trained from scratch the FNN model used in step (2) on a constructed podcast train set consisting of 10 languages (English, Spanish, Portuguese, German, French, Indonesian, Swedish, Italian, Chinese, and Welsh), corresponding to in total 10,572 hours of podcast audio (1000 episodes were sampled per language). During training, we applied a 90%/10% train/validation split with a batch size of 10 and a dropout rate of 0.4, and we trained the model for a maximum of 500 epochs.
Results
We evaluated our SLI model on a podcast audio test set with human annotated language labels for five test languages (English, Spanish, German, Portuguese, and Swedish), corresponding to in total 5,485 hours of podcast audio (1000 episodes were sampled per language). The evaluation results are presented in Table 1.
Metric––––––––Language | Precision (%) | Recall (%) | F1 (%) | AUC |
English (en) | 97.07 | 88.33 | 92.50 | 0.99 |
Spanish (es) | 93.93 | 87.67 | 90.69 | 0.98 |
German (de) | 98.15 | 88.67 | 93.17 | 0.99 |
Portuguese (pt) | 88.46 | 88.33 | 86.74 | 0.95 |
Swedish (sv) | 94.50 | 91.67 | 93.06 | 0.98 |
Average | 94.42 | 88.93 | 91.23 | 0.98 |
Table 1: Evaluation results on the long-form audio test set (podcast)
Overall, our SLI model achieved an average F1 score of 91.23% across all test languages. For benchmarking purpose, we also ran ECAPA-TDNN (a state-of-the-art SLI model trained on the VoxLingua107 dataset using SpeechBrain) on the same test set, however, the ECAPA-TDNN model failed to run inference on episodes longer than 15 minutes due to Out-of-Memory error in a standard n1-standard-4 Dataflow machine, while by contrast our system is able to run inference on episodes of five hours and longer using the same machine, and our system can analyze and predict language for an 1-hour-long audio within less than 3 minutes.
Code-Switching Spoken Language Identification
As a next step, the current system can be readily extended to predict speaker-level language(s), where we use each individual speaker embedding as input without taking average. This extension is important for code-switching audio where more than one language is spoken. We illustrate in Figure 3 how the extended system will handle a piece of code-switching audio taken from the Duolingo French podcast Episode 6: Le surfeur sans limites (The Surfer Without Limits), where the model predicts language for each turn-taking of different speakers.

Figure 3. Example of spoken language identification for code-switching audio
Conclusion
Spoken language identification (SLI) has been a challenging as well as crucial task for multilingual natural language processing, and existing SLI solutions are not readily applicable to long-form audio such as podcasts. In this work, motivated by the observation that speaker embeddings can effectively capture both speaker characteristics and language-related information, we trained a neural model for long-form audio language identification using speaker embeddings as input; the model achieves strong performance on a podcast audio dataset. We further propose code-switching spoken language identification as a next step, which is important for analyzing multilingual audio common in interviews, educational shows, and documentaries.
For more detail, please check our paper: Lightweight and Efficient Spoken Language Identification of Long-form Audio Winstead Zhu, Md Iftekhar Tanveer, Yang Janet Liu, Seye Ojumu, and Rosie Jones INTERSPEECH 2023
SHARE THIS ARTICLE

