Text2Tracks: Improving Prompt-based Music Recommendations with Generative Retrieval

Imagine asking your music app to “play some old-school rock ballads to relax” and instantly receiving the perfect track recommendation. This kind of personalized music discovery is the goal of Text2Tracks, a new system based on generative AI designed to improve how music is recommended based on your choice of words.
Why Current Methods Fall Short
Some recent music recommendation features—such as those seen in Spotify—have begun to incorporate off-the-shelf Large Language Models (LLMs) to process natural language prompts. For example, LLMs can generate artist names and song titles as their output (e.g. User: “Can you recommend some chill songs for me? LLM: “Sure, I can recommend - <ARTIST_NAME> – <TRACK_NAME> for you”).
While intuitive, the approach of identifying tracks through their title has several limitations:
Song titles are not descriptors: Song titles don’t always reflect the mood or style of the music. For example, two songs with similar names could have completely different genres or vibes.
Song titles can be ambiguous: Songs often have multiple versions (e.g., live, acoustic, remastered), and it’s not always clear which one to recommend.
Slow and costly: Song titles and artist names can be quite long. Since LLMs generate their responses one token (i.e. piece of word) at a time, generating the full title is computationally expensive and time-consuming.
To overcome these challenges, we developed Text2Tracks, a model that introduces a more efficient and effective way to recommend music by fine-tuning an LLM to directly generate optimized track identifiers (IDs) given a music recommendation prompt.
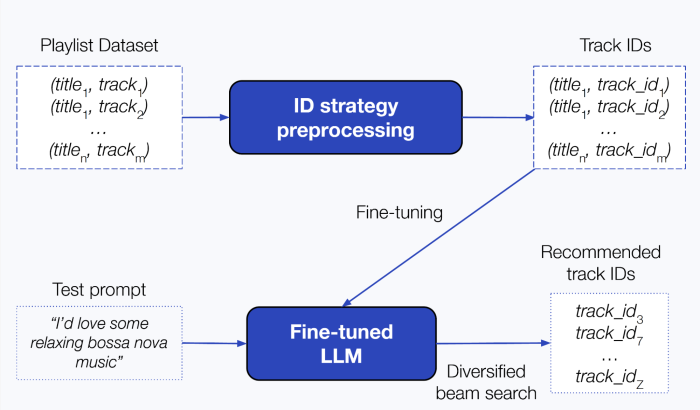
Figure 1: Text2Tracks provides music recommendation by generating track IDs that are relevant to the user’s prompt.
How Text2Tracks Works
Rather than generating actual song titles and matching them to a database, Text2Tracks uses Generative Retrieval: a Generative AI technique where the system is trained to generate track IDs directly from text prompts. These IDs directly identify songs in the music catalog and allow for faster, more accurate recommendations.
Here’s how it works (Fig. 1):
Experimenting with different strategies to create track identifiers, the playlist dataset is pre-processed obtaining pairs of playlist titles and track IDs
An LLM is fine-tuned on the pre-processed playlist data, enabling Text2Tracks to learn the relationship between user requests (like “chill acoustic vibes”) and the songs that match them.
At recommendation time, the system generates a set of IDs for songs that fit the query using a diversified beam search strategy (i.e., a decoding technique that balances relevance with diversity by exploring multiple plausible sequences, rather than just the top-ranked ones). This avoids the need for an additional search step, while still providing a relevant and diversified set of recommendations.
How Text2Tracks is Trained and Tested
A key difference between Text2Tracks and off-the-shelf LLMs is that Text2Tracks undergoes an extensive fine-tuning process tailored specifically for music recommendation. We fine-tune the model using a large corpus of selected playlists, where long and descriptive playlist titles (e.g., “energetic rock vibes,” “chill relaxing at the beach”) serve as a proxy for natural language music prompts. This allows the model to learn associations between textual descriptions and relevant track selections.
To evaluate the effectiveness of this approach, we compare the model’s recommendations to playlists curated by professional editors, using the hits@10 metric to measure how often the model's top predictions align with expert selections. This fine-tuning step helps the model better capture the nuances of music-related language and generate more relevant and contextually appropriate track recommendations.
The Role of Track IDs
One of the most innovative aspects of Text2Tracks is how it assigns IDs to songs. We experimented with three different strategies to find the best way to represent tracks (Tab. 1):
Content-Based IDs: Use metadata like artist names and song titles to build the ID (Artist Track Name). While simple and robust as a baseline, this method faces the challenges mentioned above in the “Why Current Methods Fall Short” section.
Integer-Based IDs: Assign unique integers to songs, either in a naive way where each track corresponds to a different integer (Track Integer) or in a structured way making use of the artist-track hierarchy (Artist Track Integer). This approach is easy to implement but may miss more fine-grained relationships between similar tracks, as it only relies on the track’s artist as metadata.
Semantic (Learned) IDs: use vector discretization techniques to create IDs based on song characteristics, such as genre, mood, style. For example, two holiday songs might share part of their ID (“<0><1>” and “<0><2>”), indicating their similarity. These identifiers can be seen as track “zip codes”, identifying portions of a vector space where a track lives. We tested two different vector spaces, one based on text embeddings (i.e. embedding titles of playlists where the track appears in the training set) and one based on collaborative filtering embeddings (i.e. built mining patterns of songs appearing together in playlists).
We found that Semantic IDs built on top of collaborative filtering vectors worked the best. This highlights the ability of Semantic IDs and of the underlying vector space to capture more nuances in track representations, resulting in a higher accuracy in the final set of recommendations. The Artist Track Integer strategy came in second, which is remarkable considering it's relatively simple to implement—it only uses the artist and track and doesn't need an embedding space. This shows how important the artist-track hierarchy is for modeling track identifiers and how much it can help the model learn to make good track recommendations.
It is also worth noting that the Artist Track Integer outperforms the Artist Track Name strategy, which is commonly used in many scenarios, such as off-the-shelf LLM recommendations. This further underscores the advantage of building structured track identifiers rather than identifying songs through their titles.
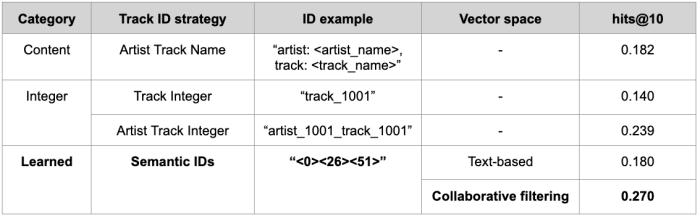
Tab. 1: hits@10 for different strategies to create track identifiers in the generative retrieval setting
How Text2Tracks Compare to Other Systems
We compared Text2Tracks to other textual recommendation methods, including:
Bi-encoders: transformer models that detect semantic matches between text prompts and songs. In the zero-shot scenario, we simply prompt the bi-encoder to match the query and the tracks. In the fine-tuned one, we fine-tune the bi-encoder on the same playlist data we use for Text2Tracks.
BM25: A state-of-the-art keyword-based retrieval system.
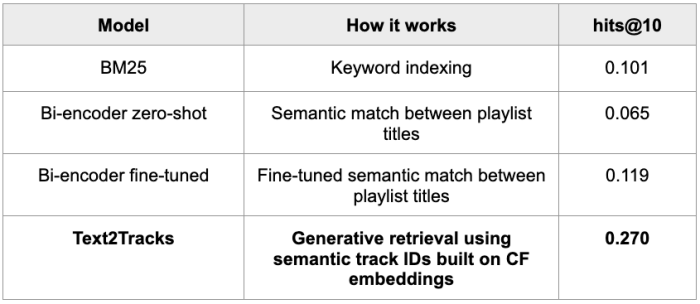
Tab. 2: hits@10 for Text2Tracks compared to well-known text retrieval approaches
We see that Text2Tracks significantly outperformed these baselines, achieving 127% better accuracy than the closest competitor. When looking into why it works so well, we qualitatively observe that it tends to recommend highly relevant and canonical tracks for broad prompts, matching the user’s expectation. For instance, when asked for “Christmas classics”, Text2Tracks reliably retrieved the most iconic holiday tracks, while other systems provided more generic holiday songs.
Looking ahead
In this post, we introduced Text2Tracks, a new approach to music recommendation that generates track IDs directly from a user prompt, delivering faster and more accurate results. Trained on playlist data and leveraging Semantic IDs built on top of collaborative filtering embeddings, Text2Tracks outperforms existing systems for prompt-based music recommendation.
These results highlight the potential of generative models to enrich music search and recommendation on Spotify. We are excited to continue advancing these technologies, with the goal of building a unified generative AI system that enhances multiple facets of music recommendation. Ultimately, we aim to make music discovery more personalized, intuitive, and enjoyable for everyone.
For more information, please refer to our paper:Text2Tracks: Prompt-based Music Recommendation via Generative Retrieval Enrico Palumbo, Gustavo Penha, Andreas Damianou, José Luis Redondo García, Timothy Christopher Heath, Alice Wang, Hugues Bouchard, Mounia Lalmas.
SHARE THIS ARTICLE
