Describe What You See with Multimodal Large Language Models to Enhance Video Recommendations
Recommending the right short- or long-form video, on TikTok, Reels, YouTube, Spotify, and beyond, remains challenging, because standard video and audio encoders capture pixels and waveforms but miss intent, parody, and world knowledge: the very reasons a clip might resonate with users and drive engagement.
Traditional video recommendation pipelines typically combine several modalities:
Text and metadata embeddings, derived from sentence encoders applied to available titles, descriptions, or user-provided tags.
Video or pooled image embeddings, obtained through keyframe encoders, 2D frame encoders (e.g., CLIP-ViT [1]), or native video encoders (e.g., VideoMAE [2]). However, many of these models face limitations with videos longer than just a few seconds.
Audio embeddings, generated from spectrogram-based CNNs or from language–audio contrastive models such as CLAP [3].
All of the above typically capture what appears on screen, what is heard, or what the uploader hopes will attract clicks, but they consistently fall short on nuances like intent, humor, parody, and world knowledge (e.g., an ironic 1990s superhero spoof filmed in Cappadocia). Our Multimodal Large Language Model (MLLM)–generated features are designed precisely to bridge that gap.
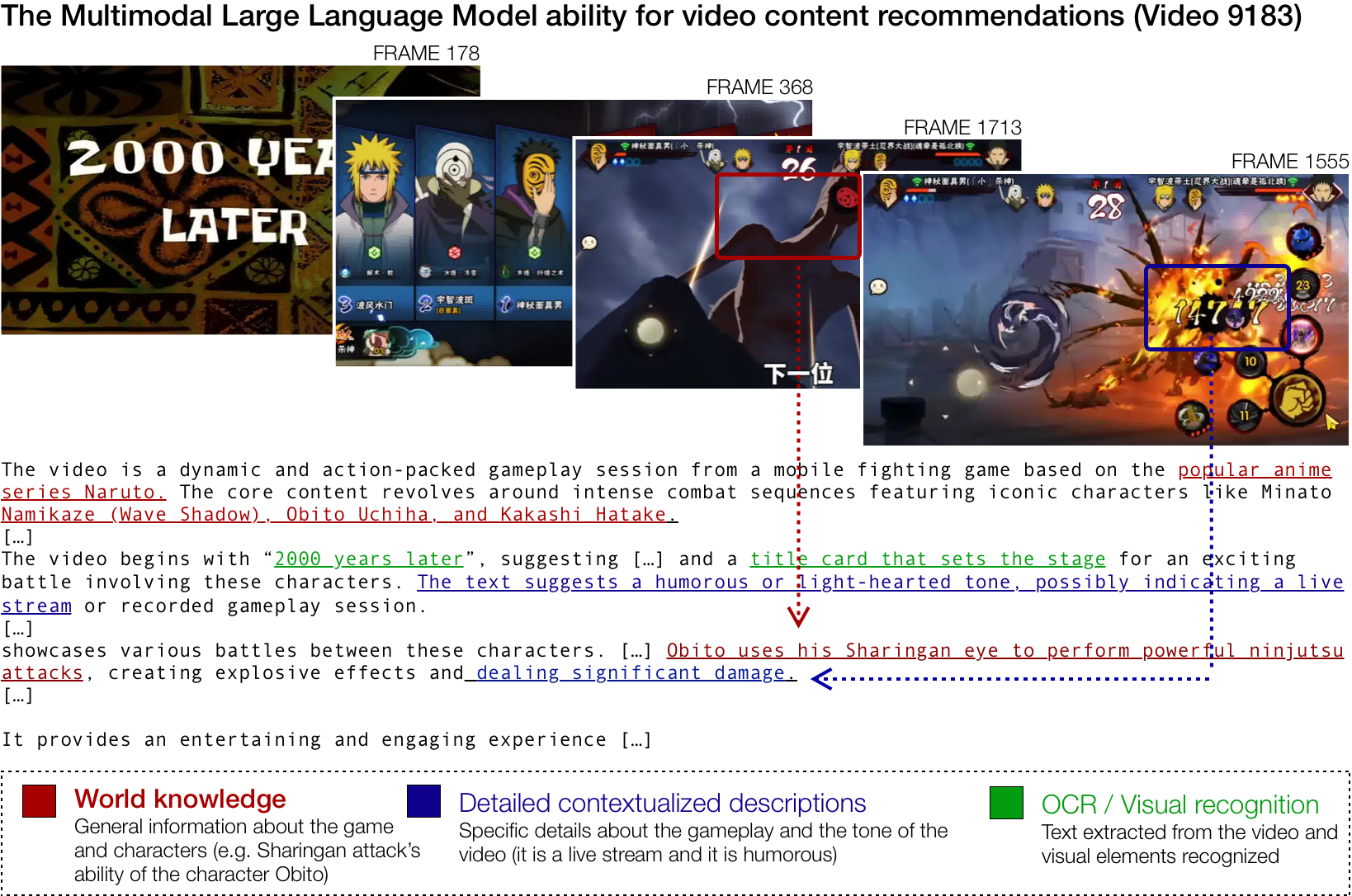
Figure: A qualitative breakdown of a gameplay clip from a Naruto mobile fighting game, demonstrating the potential of MLLMs. An MLLM (i) extracts on-screen text via OCR (green), (ii) grounds entities and actions in the franchise’s world knowledge (red), and (iii) composes fine-grained, time-aligned contextual descriptions of the battle dynamics (blue). These detailed outputs could resonate with users, thereby improving the recommendation system’s performance. Screenshots from video 9183 from MicroLens-100K [4].
The Framework
We propose a zero-finetuning, model-agnostic framework that converts each clip into a compact, world-knowledge-grounded text description, which is then fed into standard recommenders. Text is generated from the available modalities in offline mode; at serving time, the system consumes text embeddings like any other feature. On MicroLens-100K [4], these MLLM-derived features consistently outperform conventional video/audio features and sparse metadata across representative architectures.
1) Generate rich descriptions with an MLLM. We apply an open-weights MLLM (e.g., Qwen-VL [5]) over video frames to produce concise, knowledge-grounded descriptions that capture entities, actions, references, and tone. For audio, we (a) transcribe speech with Whisper [6] and (b) capture non-speech cues by prompting an audio-aware MLLM (e.g., Qwen-Audio [7]) to summarize soundtrack and mood. The result is a semantically dense text field per clip that highlights why a viewer might care.
2) Turn text into features. We encode these descriptions using a strong text encoder (e.g., BGE-large [8]) and feed the resulting vectors into the recommender, optionally alongside metadata. For comparison, raw-modality baselines use standard encoders: VideoMAE [2] for video and CLAP [3] for audio.
3) Plug‑and‑play with standard recommenders. Because all generation occurs offline, serving-time integration is straightforward: the recommender consumes text embeddings like any other feature. We evaluate the framework under two widely used paradigms: a two-tower [9] retrieval model and a generative sequential model (SASRec [10]). Importantly, no fine-tuning of the MLLM is required.
Empirical Evaluation
We conduct experiments on MicroLens-100K, a public, content-driven micro-video dataset containing raw videos, audio, and metadata collected from a real-world platform. Using a global time-based rolling split, we evaluate performance with HR@K (Hit Rate at K, measuring whether the correct item appears in the top-K results) and nDCG@K (Normalized Discounted Cumulative Gain at K, which rewards higher ranks for relevant items). The compared modalities include title metadata (text), raw audio (CLAP [3]), raw video (VideoMAE [2]), and MLLM-generated text derived from audio and video.
Key results. Converting raw audio into text descriptions improves performance by +60% in the two-tower model and +34% in SASRec [10]. Scene-level video descriptions show +24% performance gains over the video encoder only performance in the two-tower setup and +6% in SASRec [10]. Gains are especially strong for videos longer than ~30 seconds. MLLM-enhanced titles also improve results by +4% to +18%. These results show that MLLMscan improve recommendations by capturing a deeper understanding of user preferences. They are particularly effective at recognizing nuances such as location or humor, and at condensing long videos into coherent, high-level descriptions. In doing so, they address the long-horizon and semantic blindness limitations of traditional vision- and audio-based features, providing a richer and more meaningful grasp of content.
Scaling is not automatically better. In our experiments, replacing the text encoder with a larger model or using a larger MLLM variant did not yield measurable improvements. This suggests diminishing returns once the system can already generate coherent, semantically rich clip-level descriptions. In other words, beyond a certain threshold of descriptive quality, simply scaling model size does not translate into better recommendation performance.
Takeaways
This work shows that MLLM-generated features can be dropped into standard recommenders with little overhead, yet deliver significant gains.
Seamless integration. The approach fits naturally into existing stacks: teams can inject intent-aware features into two-tower retrieval or SASRec without retraining large vision models end to end. All generation runs offline, while serving simply consumes text embeddings.
Broad applicability. Built on public models and validated on a public benchmark, the recipe generalizes across platforms, product surfaces, and creator ecosystems.
For more information, please refer to our paper: Describe What You See with Multimodal Large Language Models to Enhance Video Recommendations Marco De Nadai, Andreas Damianou, Mounia Lalmas Recsys 2025, Late Breaking Results
References
[1] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." ICML, 2021. [2] Tong, Zhan, et al. "Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training." NeurIPS, 2022. [3] Elizalde, Benjamin, et al. "Clap learning audio concepts from natural language supervision." ICASSP, 2023. [4] Ni, Yongxin, et al. "A content-driven micro-video recommendation dataset at scale." arXiv:2309.15379, 2023. [5] Wang, Peng, et al. "Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution." arXiv:2409.12191, 2024. [6] Radford, Alec, et al. "Robust speech recognition via large-scale weak supervision." ICML, 2023. [7] Chu, Yunfei, et al. "Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models." arXiv:2311.07919, 2023. [8] Luo, Kun, et al. "Bge landmark embedding: A chunking-free embedding method for retrieval augmented long-context large language models." arXiv:2402.11573, 2024. [9] Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations. Recsys, 2016. [10] Kang, Wang-Cheng, and Julian McAuley. "Self-attentive sequential recommendation." ICDM, 2018.
SHARE THIS ARTICLE

