Understanding by Unmixing
Making sense of music by extracting and analyzing individual instruments in a song
Source Separation at Spotify
At the end of 2019, Spotify launched the SingAlong feature in Japan that enables users to turn down the volume of vocals in their favourite songs and sing along using time-synchronized lyrics. The response from listeners was fantastic, and many users reported how much more they engage with the music this way. In order to build this listening experience, both the vocal removal and the automatic lyric synchronization employed research we have been carrying out at Spotify for several years: unmixing music into its constituent instrument stems, also known as source separation.
The applications of source separation are vast—the SingAlong feature is just one example of how the approach can be used—as the technology enables analyzing music separately not just for vocals, drums, and bass, but any instrument. Source separation allows a musically meaningful analysis, which is not only useful for sound processing, but also for retrieval and recommendation tasks. Spotify has explored extensive research involving source separation; below is an overview of our published work on the topic so far.
The U-Net Architecture
The first Spotify paper related to source separation was published in 2017 [1]. The system is based on a straightforward principle: a music processing system should jointly analyze the sound at different time resolutions. But why is that an important aspect? Let’s illustrate this with a simple example, such as that of a recording containing only a bass line and some vocals (Fig. 1):
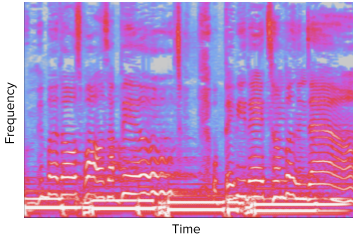
Fig 1: Spectrogram of a recording of vocals on top of an electric bass.
The bass moves slowly, sustaining notes for a longer time, while the singing voice fluctuates quickly. A system operating at a fine time resolution would be able to model the vocals precisely, however it would also be forced to analyze many time steps to identify the bass (to see which parts move slowly). Successfully modelling longer sequences, however, is often problematic in Machine Learning systems, hence one might consider designing the system to operate at a lower time resolution. Only now the voice might be so blurred that the system is unable to recognize it properly. Based on these observations, our paper proposed using a U-Net: a neural network architecture that models a time-frequency representation of a recording using a sequence of downsampling and upsampling operations, each representing the recording at a different level of detail (Fig. 2). At the time, the model’s performance surpassed the existing state-of-the-art, and recently an open-source implementation of our model was made available by researchers at Deezer.
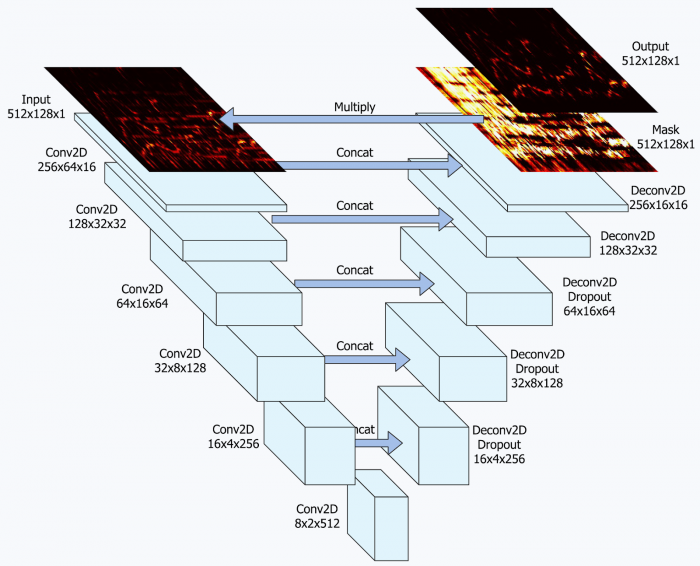
Fig 2: Illustration of the U-Net architecture used in [1].
GAN-based Training
Despite this progress, source separation remains a challenging and multifaceted task, which we continue to explore [2]. In a recent collaboration with Daniel Stoller and Simon Dixon (Queen Mary University of London), we investigated novel ways to improve source separation results using Generative Adversarial Networks (GANs). Most current systems are trained in a supervised fashion: a mixture recording is the input and the model is trained by comparing its output to the target signal (e.g. the vocals), see Fig. 3 for an illustration; this approach however is affected by several issues:
The training procedure requires paired input-output examples, i.e., multitrack recordings in which all instruments are captured in separate tracks. Unfortunately, such multitrack recordings are typically difficult or costly to obtain.
The loss used to compare the model output with the target signal is often oversimplified (typically, an l1, l2 or SDR loss). Such loss functions do not take human perception explicitly into account and thus do not prioritize the reduction of artefacts that matter most from a user’s perspective.
GANs can be used to alleviate both issues [3]. Instead of using a simple loss, a neural network (the discriminator) decides whether the output of the separator network “sounds” like a real voice or instrument, as pictured in Fig. 3. The separator and discriminator networks are trained in an alternating fashion: the separator is trained to become better at fooling the discriminators, while the discriminators are tuned to get better at distinguishing a separated instrument from a clean recording. Although GANs are typically more complex to train than a comparable supervised setup, the resulting system does not rely on paired inputs and outputs anymore: the vocals used to train the vocal discriminator do not need to be related to the vocals occurring in the mixtures used to train the separator (as long as they have similar properties, such as the language or recording conditions). Instead of multitracks, only regular (mixture) recordings and solo recordings (for each instrument to be separated) are required; this not only significantly simplifies the data gathering procedure, but also expands the potential size of the trained set.
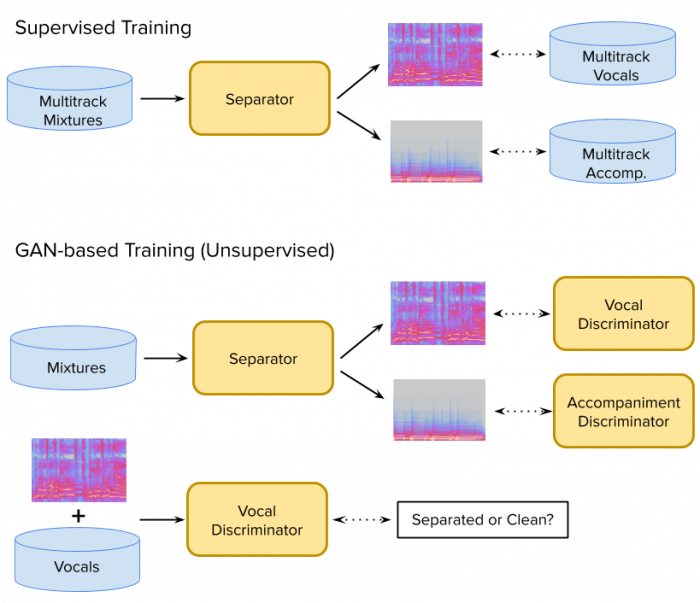
Fig. 3: Vocal Separation: Supervised and GAN-based Training.
Bringing it all together - FactorGAN
While there are clear advantages for GAN-based training if no multitrack recordings are available, the choice of which procedure to use becomes more complex in other settings. In particular, if multitrack recordings are indeed available, GAN-based training cannot exploit the clear input-output relationships that supervised training relies on, i.e. might miss a potentially rich source of information. Hybrids between supervised and GAN training are possible but, as a consequence, the separator can again only be trained using multitrack recordings; this is problematic as the separator is solving a difficult task and thus requires considerable network capacity and so would benefit from lots of data. Furthermore, the addition of a supervised loss leads to complex interactions between the losses; as a consequence, asymptotic convergence guarantees for the generator network are often lost.
In another collaboration with Daniel Stoller and Simon Dixon, we investigated how the benefits of paired and unpaired data sources can be combined, while staying entirely within the GAN framework and thus retaining its asymptotic convergence guarantees. To this end, imagine a GAN setting where a generator network is trained to transform noise into a tuple (m,a,v) of corresponding mixtures m, accompaniment a and vocals v (following the vocal separation example above). Under certain assumptions [4,5], the output of the discriminator used in this setting can be interpreted from a probabilistic perspective and corresponds to the ratio
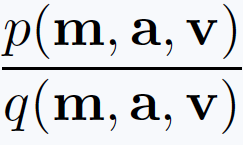
where p is the true data density for these tuples and q is the density for the output of the generator. While this scenario does not obviously reveal itself as something useful, we used this as a starting point to modify the GAN training process. In particular, this ratio of joint densities over (m,a,v) can be factorized into several ratios as follows (exploiting the fact that the mixture is the sum of the vocal and accompaniment signals):
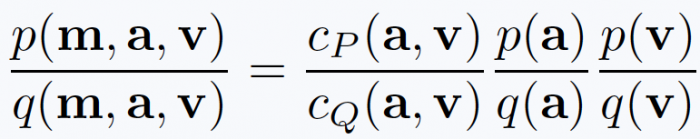
This new form captures the proposed FactorGAN training approach. The second and third terms on the right hand side correspond to a discriminator for the accompaniment and vocals, respectively, and the lack of inter-dependencies means that both can be trained independently. The cP and cQ terms correspond to two further discriminators which model whether the pair (a,v) belongs to the same piece of music or to two different ones; for cP both a and v are real recordings while for cQ both are generated by the separator. As detailed in our paper, this point of view on the discriminator leads to several advantages when building a source separation system:
Although we model a joint density, we can train instrument-specific discriminators separately using single-instrument databases.
We are able to model cross-instrument dependencies via the cP and cQ terms, but only very few multitrack recordings are required to train them.
The separator network can be trained without multitrack mixtures as input.
Although we combine multitrack and single instrument databases, we can stay entirely within the GAN setting, preserve any asymptomatic guarantees and don’t employ weak supervised losses.
This concept can be generalized much further. We applied our idea to image generation and segmentation as well, which demonstrated that our FactorGAN idea can be widely employed to enable concurrent use of paired and unpaired data.
For further details, see our ICLR 2020 paper. An implementation is available here.
References
[1] Andreas Jansson, Eric J. Humphrey, Nicola Montecchio, Rachel Bittner, Aparna Kumar, Tillman Weyde, “Singing Voice Separation with Deep U-Net Convolutional Networks”, Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2017.
[2] Andreas Jansson, Rachel M Bittner, Sebastian Ewert, Tillman Weyde, “Joint Singing Voice Separation and F0 Estimation with Deep U-Net Architectures”, Proceedings of the European Conference on Signal Processing (EUSIPCO), 2019.
[3] Daniel Stoller, Sebastian Ewert, and Simon Dixon, “Adversarial Semi-Supervised Audio Source Separation applied to Singing Voice Extraction”, Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018.
[4] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, “Generative Adversarial Nets”, Advances in Neural Information Processing Systems, 2014.
[5] Daniel Stoller, Sebastian Ewert, and Simon Dixon, “Training Generative Adversarial Networks from Incomplete Observations using Factorised Discriminators”, Proceedings of the International Conference on Learning Representations (ICLR), 2020.
SHARE THIS ARTICLE

