Shifting Consumption towards Diverse content via Reinforcement Learning
Algorithmically generated recommendations power and shape the bulk of music consumption on music streaming platforms. The ability to shift consumption towards less popular content and towards content different from user’s typical historic tastes not only affords the platform ways of handling issues such as filter bubbles and popularity bias, but also contributes to maintaining a healthy and sustainable consumption patterns necessary for overall platform success. Optimizing for diversity enables us to do so. How best can we diversify our rankings? We offer a reinforcement learning based sequencer as a solution.
Quantifying diversity
A fundamental characteristic of a music recommendation system that helps platforms shape consumption is its diversity. What does diversity mean in the context of music recommendation? First, it can facilitate exploration by helping users discover new content or inculcate new tastes. Additionally, it can help the platform spread consumption across artists and facilitate consumption of less popular content. Finally, it has recently been shown that a diverse consumption of music [1] is strongly associated with important long-term engagement metrics, such as user conversion and retention.
We formalize our notion of diversity around two central factors that influence music consumption via recommender systems: taste similarity and popularity. To expand user’s taste profiles, we consider user taste based diversification wherein we recommend music content that is sufficiently different from user’s known preferences. We compute user-track similarity to quantify this specific form of diversity. To foster popularity based diversification, we wish to diversify music consumption to include less popular content, and use the global popularity estimate of a track to quantify this notion of diversity.
Diversity and User Satisfaction
We investigate how the notions of diversity are related to relevance and overall user satisfaction. Relevance of a track to a user is defined as a binary function, which is 0 if the user skipped the track and otherwise 1. Overall user satisfaction here is measured by session length, which corresponds to the number of listened tracks within a session.
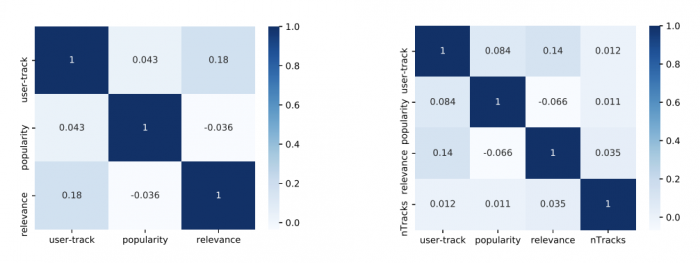
Looking at music consumption data of a random sample of 1 million user sessions, and 2 million music tracks, we observe from the correlation plots (left figure above) that user-track similarity is positively correlated with relevance, whereas popularity is not correlated much with relevance. This indicates that reducing user-track similarity potentially can negatively impact user satisfaction, while popularity could likely be reduced without impacting user satisfaction. Further, looking at session level correlations (right figure above), we observe that the average popularity is not correlated to either overall user satisfaction or average relevance. User-track similarity is correlated with relevance, but interestingly it is not correlated with overall user satisfaction. This gives us a first glimpse at the possibility of recommending less popular and less similar content without potentially negatively impacting overall user satisfaction.
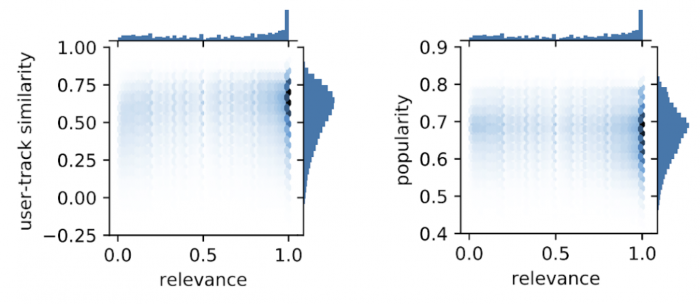
Going beyond the global aggregate correlations, we next look at data across different sessions, and consider the distribution of diversity measures within a session with regard to average relevance of the session (figure above). We observe that the highest density is at high popularity/user-track similarity and at fully relevant sessions, but there is considerable density outside this area. Sessions exist where users are not satisfied with the most popular tracks (upper left side), and there are sessions where they are satisfied with low popularity tracks (lower right side). The same can be observed for user-track similarity.
Our analysis underpins the scope for shifting consumption towards diverse content, and suggests that it is indeed possible to shift consumption towards more diverse recommendations without negatively impacting user satisfaction, and highlights that the typical focus on high popularity/user-track similarity can be detrimental for some sessions. Based on the above motivation, we shift our focus to the main goals of our research: how can we develop diversity aware track sequencers for users?
Reinforcement Learning Sequencer for Track Sequencing
We consider the problem of sequential recommendation in a session, where a user consumes a series of recommended music tracks. We considered four different rankers of increasing complexity: relevance ranker which uses cosine similarity between user and track, feedback forward neural model trained to predict the probability of a user skipping a track, a feedback aware neural model that extends the feed forward ranker and incorporates the user’s previous sessions to compute a dynamic user embedding, and a reinforcement learning based sequencer. While the paper describes each of these in detail, here in this blog we focus on the reinforcement learning sequencer.
Recent progress in reinforcement learning (RL) has achieved impressive advances in games as well as robotics. RL in general focuses on building agents that take actions in an environment so as to maximize some notion of long term reward. Here we explore framing recommendations as building RL agents to maximize user satisfaction with the system, or developing RL agents to jointly consider user satisfaction and diversity goals when surfacing recommendations to users. This offers us new perspectives on recommendation problems as well as opportunities to build on top of recent RL advancements.
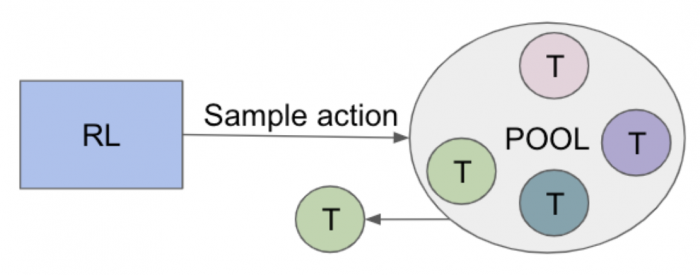
Track Sampling based RL Sequencer
Our proposed RL sequencer is a sampling-based sequencer that samples a single track from a set of tracks as the recommendation, which depends on the previous recommended tracks. This process is repeated on the remaining set of possible tracks to produce a ranked list.
We formulate the problem of ranking as a standard reinforcement learning problem with a policy 𝜋(𝑡|𝑠) that gives the probability of sampling track 𝑡 from a candidate pool of a few thousand tracks given state 𝑠. The policy ? is learned so it maximises some notion of reward 𝑅(𝑡, 𝑠), which gives some reward for recommending track 𝑡 at state s. We describe the end-to-end system in detail, starting with the description of different neural components, followed by details of the user state representations and the reward model used to train the system.
Neural Components
We define the various neural modules built to extract information from sessions and learn embeddings used in the main RL sampler. The overall network is composed of three key components: (i) session summarizer, (ii) dynamic user embedding, and (iii) feedback aware ranking module.
1. Session summarizer: Summarizing a single session
Each session (𝑠) consists of session level meta features (M) and a sequence of tracks (T,R) ∈ 𝑠, where T is the track level features and R is an indicator of whether the user found the track relevant. The session is summarised using a long short-term memory (LSTM) followed by an attention softmax layer, as shown in the figure below. Later on, we describe the state ? as a sequence of tracks the user previously has been recommended in the session, in addition to the session meta representation (M).
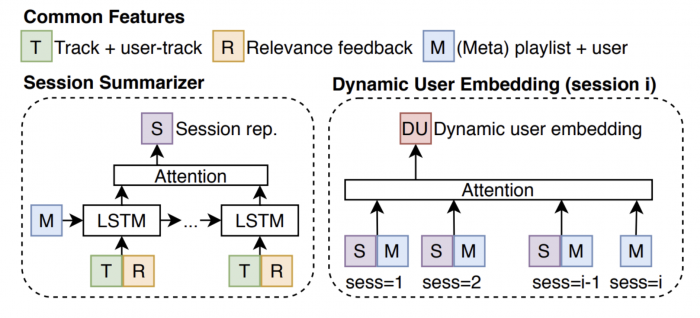
2. Dynamic User Embedding
After summarizing a single session, we look across all recent sessions for a user, and summarize all sessions to a final dynamic user embedding. At time point 𝑖, the users have a set of previous session embeddings, 𝑆𝑗∈ S, 𝑗∈ [1,𝑖− 1], each having associated meta information 𝑀𝑗. The dynamic user embedding is a summary of all previous session embeddings, conditioned on the current sessions meta information 𝑀𝑖. The summarisation of previous sessions is done by attention weighting, where the weighting is based on an interaction vector between the current session meta information, and the historic sessions meta information. The interaction vector is the concatenation, subtraction, and multiplication of the past session and current session meta representations, to capture the representational changes between sessions. The feedback aware track score is then computed via a feed forward ranker which takes as input the track level features (T) and session level meta features (M), along with the dynamic user embedding (DU) as an additional input. This module is optimized using cross entropy loss.
3. Feedback aware neural module
The feedback aware neural module makes use of the dynamic user embedding, and helps compute the intermediate representations, which form a key component of the state representation of the RL sequencer. The goal of this module is to incorporate the user’s dynamic user embedding, along with track and playlist metadata to predict a single score. As shown in the figure below, the feed forward network consists of two hidden layers with ReLU activation functions, and a prediction layer using a sigmoid activation function. This prediction corresponds to the probability of a user skipping a track, which is optimized using cross entropy loss. The network is indirectly aware of the users history through the user embedding and the user-track features.
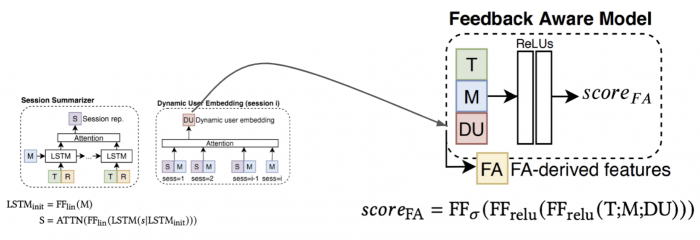
We use these three neural components to define the track and state representations, which form a key component of the RL sequencer.
State Representation in RL
Before we cover how the policy 𝜋 ( 𝑡 | 𝑠 ) is computed, we first define how 𝑡 and 𝑠 are represented for the RL sequencer. 𝑡 is the track level features (denoted as T in the figures), but also concatenated with derived features from the feedback aware module described above. The derived features are the second and last layer of the feedback aware module for each track; we denote this set of derived features as FA. These features are included to provide a richer representation to the RL model, which incorporates the user’s past feedback. The state 𝑠 is a sequence of tracks the user previously has been recommended in the session, in addition to the session meta representation (M). The state is encoded using a stacked LSTM with two layers, and initialised based on a linear projection of the session meta information:
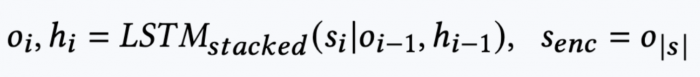
where LSTM𝑠𝑡𝑎𝑐𝑘𝑒𝑑 is a stacked LSTM with two layers, and s𝑒𝑛𝑐 is the last output of the stacked LSTM.
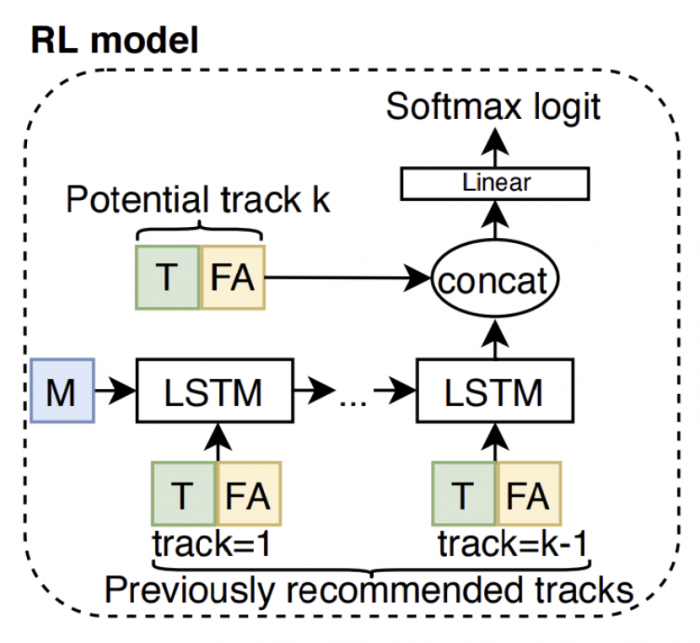
Track Sampler
We want to find a policy 𝜋(𝑡|𝑠) that gives the probability of sampling track 𝑡 given state 𝑠. The policy 𝜋 is learned so it maximises some notion of reward 𝑅(𝑡, 𝑠), which gives some reward for recommending track 𝑡 at state 𝑠. We therefore have to define the sampling probability 𝜋(𝑡|𝑠) and the reward 𝑅(𝑡, 𝑠). We use the state representation described above, and compute the sampling probability of a track using the logit function. Given a candidate pool of tracks, the logit for each track 𝑡 in the set of possible tracks, T, is computed as:
Both session encoding and track representation are passed through a linear feed forward layer, then concatenated and run through a feed forward layer using a ReLU activation function, followed by a linear output that gives the unnormalised logit for the track. The unnormalised logit is computed for all tracks in the set of possible tracks, and the sample probability is found by applying a softmax.
The softmax of the logit for each track gives the final sampling probability, based on which the tracks are sampled.
We recall that our goal is to find a policy 𝜋(𝑡|𝑠) that gives the probability of sampling track 𝑡 given state 𝑠. The policy 𝜋 is learned so it maximises some notion of reward 𝑅(𝑡,𝑠), which gives some reward for recommending track 𝑡 at state 𝑠. We next describe the reward function used to train the model
Reward Formulation
The reward associated with a sampled track, 𝑡∼ 𝜋(·|𝑠) is defined based on whether the user found the track relevant. Specifically, we define the reward as:
where 𝑟 is a binary relevance function, which is 0 if the user skipped the track and otherwise 1. 𝑐 is a small constant that ensures that a negative reward is assigned to non relevant tracks. For all our experiments 𝑐 was fixed at 0.1.
Beyond user satisfaction, our goal is to foster diversity in the recommendations surfaced to users. To this end, we encode the notion of diversity in our reward formulation as another objective. RL allows us to optimize multiple objectives directly by modifying the reward function. Thus, for the RL sequencer we introduce diversity by including a diversity term in the reward function:
where d(t,u) ∈ [0,1] quantifies the diversity value of the track, and 𝑡 is a trade-off parameter between diversity and relevance. Diversity is multiplied with relevance, such that it is only beneficial to recommend diverse tracks when they are relevant to the user. The overall model is trained using the REINFORCE algorithm.
Experiments & Results
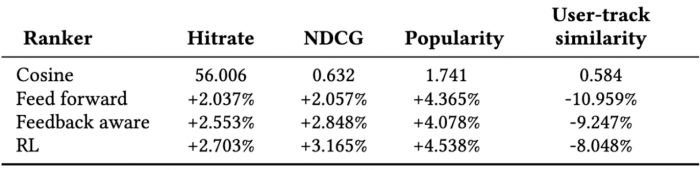
We observed strong associations between diversity, relevance and extent of user satisfaction. The natural follow up question is how different rankers and diversity inducing methods fare, in terms of key satisfaction and diversity metrics. We compare the proposed RL model with a number of baseline rankers: cosine ranker, simple feed forward ranker, and feedback aware ranker. Comparison across such methods provides us with a wide spectrum of approaches, from simple similarity based rankers to sophisticated reward based RL sequencer, and enables us to understand the interplay between model complexity and performance. Given their modeling sophistication, we rank the different rankers as relevance (cosine) ranker < feed forward < feedback aware < RL sequencer, as an increasing order of model complexity.
To investigate how different diversity incorporation techniques fare, we compare with three ways of injecting diversity into ranking models:
Linear interpolation: We do a weighted sum of the predicted relevance score and diversity score.
Submodular diversification: Diversity is introduced by formulating the diversity problem as a submodular set function.
Interleaving: Diversity is introduced by alternatively recommending tracks with high diversity and high relevance scores. We sort the tracks into two lists, relevance list and diversity list, and sample with probability 1− 𝛼 from the relevance list and otherwise from the diversity list at each time step, where 𝛼 controls the trade-off between relevance and diversity. After each recommendation, the recommended track is removed from both lists.
We conduct offline experiments on a dataset consisting of the listening history over a 2 month period of a sample of 1 million of users across 20 million sessions. Here, we measure user satisfaction with the served recommendations using Hit Rate – the percentage of recommendations relevant to the user (recommendations that the user listens to), as well as Normalised Discounted Cumulative Gain (NDCG). For diversity centric experiments, we consider the average popularity of the recommended content (Popularity) and average user-track similarity for recommended tracks (User-track similarity) as our diversity metrics. To avoid revealing sensitive metrics, we introduce a multiplicative factor to the base metrics reported.
How do different rankers perform on Satisfaction and Diversity metrics?
We begin by investigating the trade-off between model complexity and performance, and investigate how the different rankers fare on diversity metrics when not optimized explicitly for diversity. We observe (table below) that as the increasingly complex rankers lead to higher user satisfaction, they also result in recommendations with a higher average popularity. Most notably, the largest popularity increase occurs when going from the cosine ranker to any of the neural rankers. These results suggest that while increasing model complexity gives better user consumption predictability, it comes at a cost of decreased diversity. This motivates the need for explicitly encoding diversity into the ranking model.
How effective are different ways of diversification?
To evaluate the different diversity inducing approaches, we compare their performance for introducing diversity against each other, keeping the ranker fixed. For the three methods requiring a track relevance score (interpolation, submodular, and interleaving) we use the feed-back aware ranker as the base ranker.
For popularity diversity (figure below, left), we observe that the RL method obtains the best trade-off between high hit rate while reducing the average popularity. This shows a small benefit of using RL to reduce the average popularity, but at the cost of higher computational complexity and training time compared to the simple linear interpolation. For user-track similarity based diversification (figure below, right), we observe that the RL method and linear interpolation obtain very similar trade-offs, but that the linear interpolation cover a wider range of trade-offs than the RL method. These findings suggest that leveraging RL reward modeling for diversification gives slightly better performance, but interpolation based methods offer a wider range of trade-offs, which provides more flexibility and control to system designers.
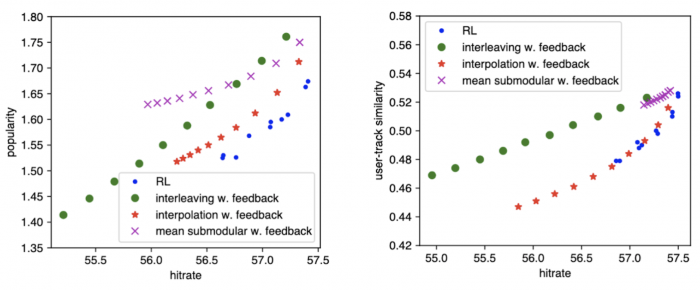
We observe that RL diversity reward and linear interpolation work better than interleaving and submodular diversity methods. Interestingly, comparing these results with the ranker comparison on only satisfaction, we observe bigger differences in hit rate when rankers consider diversity, than when they are only focused on satisfaction. This suggests that when one cares only about satisfaction, the difference between rankers is less pronounced. However when one cares additionally about diversity, the difference between rankers becomes more pronounced.
Does diversity help in shifting consumption?
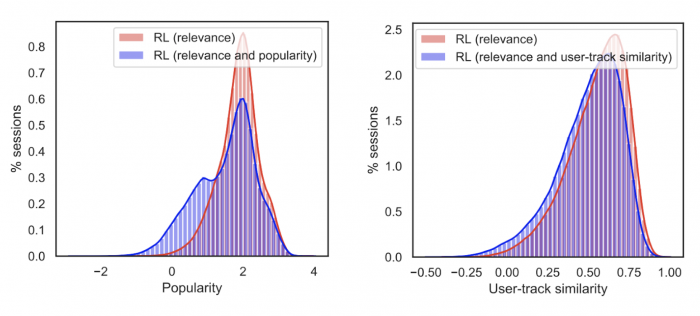
We find evidence that not only are users satisfied with relevant recommendations, but also often with recommendations that depart from their historic tastes, or are less popular. Such departure from relevant and popular content allows platforms to broaden the scope of music listening and shift consumption towards the tail and less familiar content. The figure below visually depicts this shift in consumption, wherein we observe a significant shift in popularity distribution from unimodal to bimodal when additionally optimizing for popularity diversity, and a slight shift towards lower user-track similarity when optimizing for similarity diversity.
Conclusions
Looking at music consumption data, and presented results, we found evidence that not only are users satisfied with relevant recommendations, but also often with recommendations that depart from their historic tastes, or are less popular. Such departure from relevant and popular content allows platforms to broaden the scope of music listening and shift consumption towards the tail and less familiar content.
We argue that while cosine rankers are a good first solution to the recommendation problem - being greedy algorithms, they are quick to deploy, and offer comparable performance to neural and RL sequencers if satisfaction is the only goal. However, if diversity is important to consider, and as systems mature and the need for improved models arises, switching to neural ranker or RL sequencer makes sense, since they offer increased performance on user satisfaction metric. On the choice between different ways of diversification, the reward modeling based RL method performs better than interpolation for swaying consumption away from popular content. The increased modeling and deployment complexity indeed brings in performance gains.
More details can be found in our recent WSDM 2021 full paper: Shifting Consumption towards Diverse Content on Music Streaming Platforms Christian Hansen, Rishabh Mehrotra, Casper Hansen, Brian Brost, Lucas Maystre and Mounia Lalmas WSDM 2021
References
[1] Ashton Anderson, Lucas Maystre, Ian Anderson, Rishabh Mehrotra and Mounia Lalmas. "Algorithmic effects on the diversity of consumption on spotify." In Proceedings of The Web Conference 2020, pp. 2155-2165. 2020.
SHARE THIS ARTICLE

