Identifying Promising New Podcasts

A large number of new podcasts are launched every month on Spotify and other online media platforms. In this work, we study ways to identify new podcasts that are likely to appeal to large audiences. These podcasts could then be fast-tracked for editorial curation and recommendation to users.
A common approach to identifying promising new podcasts is to train a supervised model to predict the audience size of a podcast based on the performance of more established podcasts. We explored such a model and ran into a limitation: although we were able to predict the future popularity of new podcasts fairly reliably, the podcasts we identified were often from creators who already have a large audience outside of podcasting or a large social media following. These factors can help a podcast to grow, but do not directly correspond to how much listeners will enjoy them. That is, popularity for new podcasts is often a measure of the audience already established by the creator or existing social media followings on other platforms rather than a direct measure of listener preference. As shown previously in the literature [1], popular items tend to become more popular independent of their “quality.” To account for this, we defined a concept we call “general appeal,” which is the number of users who would stream a podcast if they were exposed to it in a controlled randomized trial.
We find that predicting popularity and audience growth potential are not the same thing and that some machine learning features can be sub-optimal. To resolve this, we propose a novel non-contextual bandit algorithm particularly well-suited to the task of identifying podcasts with high general appeal. We showed that its performance is competitive with the best-known algorithms for this task, and that it is better suited when the user’s response to a recommendation takes some time to measure.
Our Supervised Approach
We first examine how to predict a podcast’s future audience size using a supervised model. We compared several off-the-shelf machine learning models with three sets of features. The features were used to predict the number of streams on day 60-90. We use two categories of features:
consumption features: we included the number of streams of a podcast and its total number of hours streamed as well as the number of users who streamed and who followed the podcast. The features were computed over various 30 day windows, using statistics for the first 30 days and days 31-60. We also used statistics as of the podcast’s launch day.
content features: we include the podcast’s topic, information about the length and readability of its description, whether any social media accounts are listed in its description, and statistics about its number and frequency of episode publication.
We trained our models using the following three sets of features: just consumption features, just content features, and both consumption and content features. Our SortByPopularity baseline picks the top k podcasts as sorted by the number of streams in the prior 30 days. To evaluate, we predict the number of streams at 60-90 days for each podcast in our test set and pick the top k predicted to have the most streams. We report precision@k for each method in the table below.
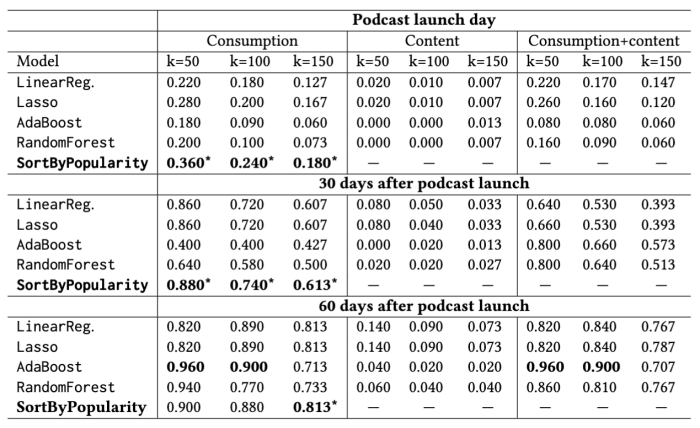
We found several interesting results. In the first place, the content features produce better-than-random predictions, so they do contain some predictive power, but they do not perform as well as the consumption features. Combining the content and consumption features tends to produce a worse result than using the consumption features alone. Although content features did not help with predicting potential audience sizes, we expect them to be more important for other tasks such as recommendation tasks. When recommending content to a particular user, we may want to leverage content features to match content specific to a person's preferences. The types of content features we might expect to be most important for predicting audience size are the most difficult to produce, e.g. the host’s charisma and novel aspects of the podcast. Our second main finding is that SortByPopularity outperforms all our supervised models except for AdaBoost 60 days after launch. In our work, we examine AdaBoost more closely and find that the additional signals it uses to improve on SortByPopularity are mainly the other consumption features.
To summarize, the best way to pick the most-streamed podcasts in days 60-90 after launch is to pick the most-streamed podcasts earlier in their lifecycle. A podcast’s performance relative to other podcasts of its age is strongly predictive of future performance, so podcast streaming appears to strongly exhibit “rich-get-richer” dynamics.
Problems with a Supervised Approach
We have found that early streaming is predictive of future streaming, which could potentially be explained in many ways. It could be that some podcasts succeed both early on and in the coming months, in which case popularity would be a reliable indicator of a podcast’s potential audience size. However, a large body of research suggests that this is not likely to be the case: many factors other than listener preference can drive streaming. We provide two pieces of evidence in our paper that such factors contribute to the number of streams between days 60 and 90 post podcast launch, suggesting that podcasts that have the potential to be very popular but that do not naturally obtain the same level of streaming may be overlooked.
The first sign that popularity is not a reliable indicator of listener preference was based on a manual inspection of the top 100 podcasts sorted by streams between days 60 and 90 post-launch. Most of the top streamed podcasts were created by people who already have a large audience outside of podcasting and/or have existing social media followings on other platforms. Estimators of a podcast’s potential audience size that are independent of a podcast’s current popularity allow us to surface more podcasts whose creators may not yet be famous.
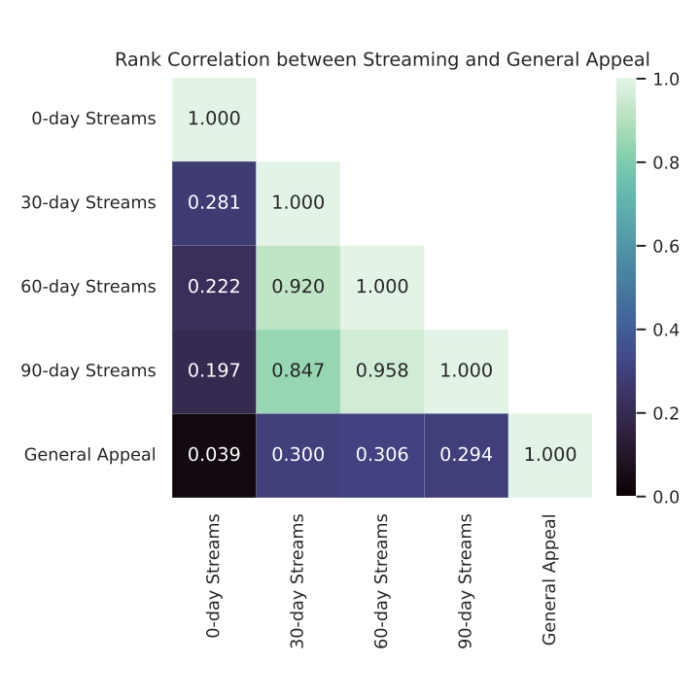
For our second piece of evidence that popularity is not identical to potential audience size, we directly measured the general appeal of a collection of podcasts. We define “general appeal” as the number of users who would stream a podcast if shown it in a controlled random trial. This value corresponds to the podcast’s potential audience size if enough people knew about the podcast. We conducted such a trial for a population of 700 podcasts and measured their general appeal. When we looked at the correlation between their general appeal and their stream counts (below), we found that the numbers are only slightly correlated. In this trial, popularity and general appeal had a rank correlation of only around 0.3, which suggests that some of the most-streamed podcasts had relatively low general appeal and that some of the most appealing podcasts had relatively few streams.
Put together, these pieces of evidence suggest that a supervised approach to identifying new podcasts with large growth potential has limitations. We next discuss an alternative approach.
Our Bandit Approach
Ideally, we would be able to directly measure the general appeal of all podcasts and use that information for recommendation. That would consist of continually running a random experiment in which each podcast would be shown to many users chosen at random. Given the large number of podcasts being created each month, this would mean we would be constantly showing many users podcasts that they are typically uninterested in, which creates a poor experience for those users. Instead, we want to be more strategic: we want to use as few users as possible to identify the best new 100 or 1,000 podcasts, without precisely measuring the general appeal of all podcasts in the process.
This task, selecting the top k items from a very large pool, is called the Fixed-Budget Infinitely-Armed Pure-Exploration Non-contextual Bandit problem. It is “fixed-budget” because we want to recommend podcasts to a small number of users, i.e. the user budget we use is fixed ahead of time; it is “infinitely-armed” because we have too many “arms” (podcasts) to be able to measure them all precisely; it is “pure-exploration” because we want to focus on efficiently identifying the best podcasts; it is “non-contextual” because we are not using any features for the task.
We have created an algorithm, which we call ISHA, to efficiently solve this problem. A particular challenge for this task is that we have delayed rewards: it takes a substantial amount of time for users to respond to recommendations, so the algorithm cannot assume it will receive feedback instantaneously. The variant of our algorithm called Unforgetful ISHA has competitive performance with the best algorithms for this problem in terms of accurately finding the best podcasts, and at the same time, it is dramatically faster than its competitors in a delayed reward setting.
We measure how accurately the algorithm is able to identify the best podcast given a fixed number of users (its “budget”) using a measure called simple regret, which is the difference between the general appeal of the podcast the algorithm chose and the general appeal of the best available podcast. The graph below compares the performance of Unforgetful ISHA with several baseline algorithms. The three best algorithms in terms of simple regret are Unforgetful ISHA, Successive Rejects, and Empirical CBT. These algorithms are the most efficient at identifying the best podcasts with the fewest number of users.
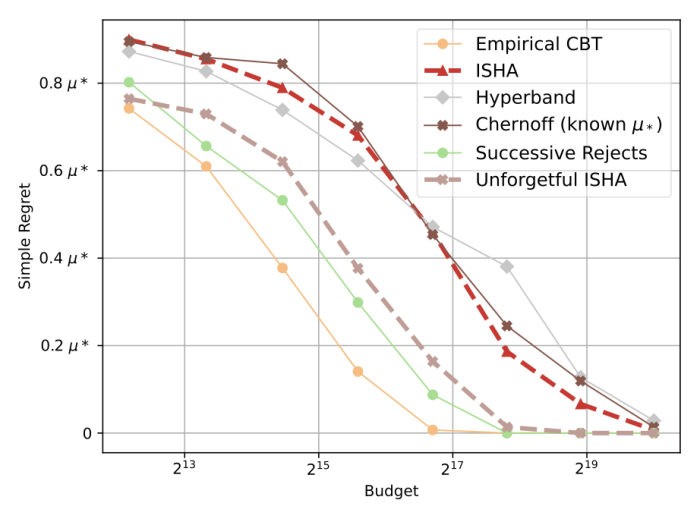
However, it is also important that the algorithm be able to complete in a reasonable amount of time. Most bandit algorithms assume instantaneous rewards, but in practice, each arm pull (podcast recommendation) depends on human feedback and so it can take an appreciable amount of time to measure the reward. For example, was the podcast streamed within 24 hours of the recommendation? This duration constrains the duration of each round of the algorithm. Say if we were interested in finding the best of 32,000 new podcasts each month and the feedback took 24 hours. Unforgetful ISHA would only take two weeks to complete, which is asymptotically faster than Successive Rejects and Empirical CBT. Only Unforgetful ISHA is able to complete in a reasonable amount of time in this delayed reward setting.
Final Thoughts
Identifying the most promising new podcasts with a minimal impact on podcast listeners is crucial. Whilst we can easily identify podcasts that, on their own, will obtain the most user streaming, it is harder to identify podcasts that users actually enjoy the most. Our algorithm, Unforgetful ISHA, makes it possible to identify such podcasts as they are released, with a small enough number of required users and a fast enough runtime in a delayed feedback setting to keep up with the rate at which podcasts are introduced.
Identifying New Podcasts with High General Appeal Using a Pure Exploration Infinitely-Armed Bandit Strategy Maryam Aziz, Jesse Anderton, Kevin Jamieson, Alice Wang, Hugues Bouchard, Javed Aslam RecSys 2022
References
[1] Experimental Study of Inequality and Unpredictability in an Artificial Cultural Market Matthew J. Salganik, Peter Sheridan Dodds & Duncan J. Watts.
SHARE THIS ARTICLE

