Unsupervised Speaker Diarization using Sparse Optimization

What is Speaker Diarization?
Speaker diarization is the process of logging the timestamps of when various speakers take turns to talk within a piece of spoken word audio. The figure below shows an audio timeline, annotated with the regions where different speakers were audible.
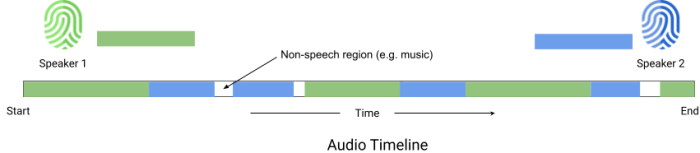
Illustration of speaker diarization
Challenges
Classic approaches to speaker diarization follow an unsupervised process. This approach, however, suffers from a number of issues. First, typical clustering methods, like spectral clustering, utilize a non-overlapping assumption among the clusters, which makes the overlap detection an additional step and complicates the overall algorithm. Second, the total number of clusters need to be pre-specified, which can be challenging. Third, the process of computing the embeddings often utilizes language-specific cues, such as the transcription of the audio. Such language-dependent embeddings are difficult to scale over multiple languages.
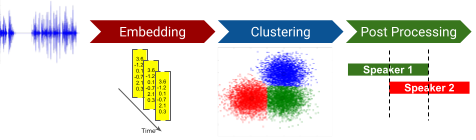
Classic diarization approach
Supervised algorithms for diarization also exist, and are trained end-to-end using labeled data. However, these algorithms have their own challenges. For example, the training dataset is typically imbalanced, which can lead to bias over specific age, gender, or race and can lead to unfair prediction. To address this issue, the training dataset must be balanced over many attributes (age, gender, race etc.) of the speakers. For diarization applications on real world scenarios like podcasts, the training data also needs to be balanced for different categories and formats of content. Counterbalancing is difficult, as it grows the dataset exponentially. Finally, preparing a supervised training dataset can be expensive and time consuming due to the annotation of diarization data.
Proposed Solution
In this work, we proposed a solution that avoids these challenges by utilizing a sparse optimization method. This solution is unsupervised, language-agnostic (thus scalable), and overlap-aware. We utilize a voice embedding that uses audio-specific cues only. It is also tuning-free – i.e. doesn't require the users to pre-specify the exact number of speakers in the audio.
In our algorithm, we preprocess the audio signal using a Voice Activity Detection step. We use YAMNET from Tensorflow hub [1] for detecting the voiced regions in the audio. Then, we compute the VggVox embeddings [2] for small, overlapping time segments of the audio. We call the sequence of these embeddings for a podcast the embedding signal. We formulate a sparse optimization problem to factorize the embedding signal into the corresponding embedding basis matrix and the activation matrix. The optimization problem attempts to reconstruct the embedding signal with a minimum number of distinct embeddings (basis). We also propose an iterative algorithm to solve the optimization problem.
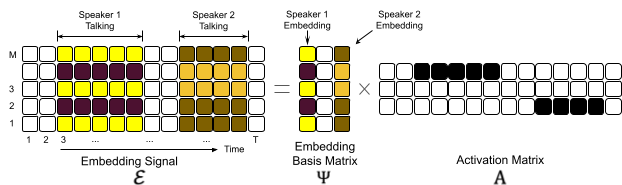
Speaker diarization expressed as a matrix factorization problem
Advantages of the Solution
This approach is overlap-aware. The VGGVox embedding of an audio, where two different speakers are present, is roughly equivalent to the weighted average of each speakers' embeddings. This characteristic, along with the sparsity constraint, penalizes constructing a new embedding for the overlapping regions as shown in the following figure. This makes the optimization algorithm to model the overlapping regions as a linear combination of the two existing embeddings.
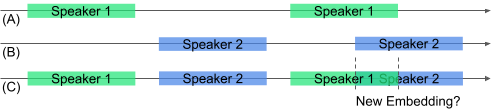
Illustration of overlap-awareness
Due to the sparsity constraints, this approach doesn't need to specify the exact number of speakers. It requires selecting a maximum number of speakers which we do by leveraging a technique from linear algebra. We apply Singular Value Decomposition (SVD) over the embedding signal. The singular values are sorted in descending order. The knee of this sequence is then detected using a knee detection algorithm. The knee location is multiplied by a factor of 2.5 to estimate the maximum number of speakers. The factor 2.5 gives us a useful margin of error for the upper bound of the number of speakers.
Experimental Results
We evaluate our diarization algorithm against a commercial baseline, an in-house implementation of a spectral clustering algorithm, two open source solutions, and two naive approaches. As an evaluation dataset, we used a well-known public radio-turned-podcast series. It contains podcast audio which is typically an hour-long and contains 18 speakers on average. As evaluation metrics, we use diarization error rate, purity, and coverage. Purity and coverage are the equivalent of precision and recall for the diarization problem, and we also report the F-score, the geometric mean of purity and coverage. As a commercial baseline, we use the diarization solution provided with the Google Cloud Platform transcription service. The results show that our algorithm outperforms the commercial baseline in all the different metrics for the tested dataset. For a detailed discussion of this result, along with some other experiments, please check out our paper:
Unsupervised Speaker Diarization that is Agnostic to Language, Overlap-Aware, and Tuning Free M. Iftekhar Tanveer, Diego Casabuena, Jussi Karlgren, and Rosie Jones INTERSPEECH 2022
References
[1] https://www.tensorflow.org/hub/tutorials/yamnet [2] A. Nagrani, J. S. Chung, W. Xie, A. Zisserman, Voxceleb: Large-scale speaker verification in the wild, Computer Speech and Language, 2019
SHARE THIS ARTICLE



