Which Witch? Artist name disambiguation and catalog curation using audio and metadata

TL;DR
We developed a Named Entity Disambiguation (NED) method to assist human curators in finding and correcting infrequent errors in a music catalog. This system can detect misattribution, when releases that are incorrectly attributed to an artist discography and predict suitable relocations, and duplication, when the discography of an artist is incorrectly split.
To do this, the system combines audio vector representations with metadata-based features in a machine learning (ML) system. Combining audio and metadata models outperforms models based on audio or metadata alone. Through a set of “in-the-wild” experiments with Subject Matter Experts (SMEs), we demonstrate the potential of such proactive curation systems to save time and effort by directing attention where it is most needed to ensure that our catalog is free from errors.
Named Entity Disambiguation at scale
Named Entity Disambiguation deals with the problem of mapping ambiguously named entities, such as homonym music artists, to their correct identifiers. For example, on Spotify there are 11 artists named Witch (plus many others with Witch in the name). When a new release by a Witch is submitted without a unique artist identifier, we must make a decision of where to place it: Is it by the Zambian psychedelic band, the US doom metal band, one of the other Witches, or a new Witch? Given the extremely large volumes of music content delivered to Spotify every day by providers that vary from DIY artists through aggregators, all the way to megastars through major labels, it is inevitable that occasionally a release is incorrectly attributed.
In Music Information Retrieval (MIR), NED is typically formulated as a multi-class classification problem with known artist classes. This formulation, which relies primarily on audio feature representations, cannot be applied to Spotify-scale catalogs with a large or even unknown number of artists; a number that grows every day. State-of-the-art NED research has focused recently on automation; however, a human-in-the-loop (HITL) paradigm is often necessary to resolve highly ambiguous cases, correct automated decisions, and ensure quality.
Our solution
In this paper, we present an ML-based semi-automated proactive curation system to detect and correct attribution errors in large music catalogs. The system consists of two sub-models (which can be standalone systems): detects misattribution by splitting discographies with releases from multiple artists into single-artist discographies (Figure 1a), and another detects duplication by deciding whether two discographies belong to the same artist and should be merged (Figure 1b). Both systems rely on the music’s metadata and the acoustic similarity between releases, using deep convolutional network embeddings of their mel-spectrograms and random forests.
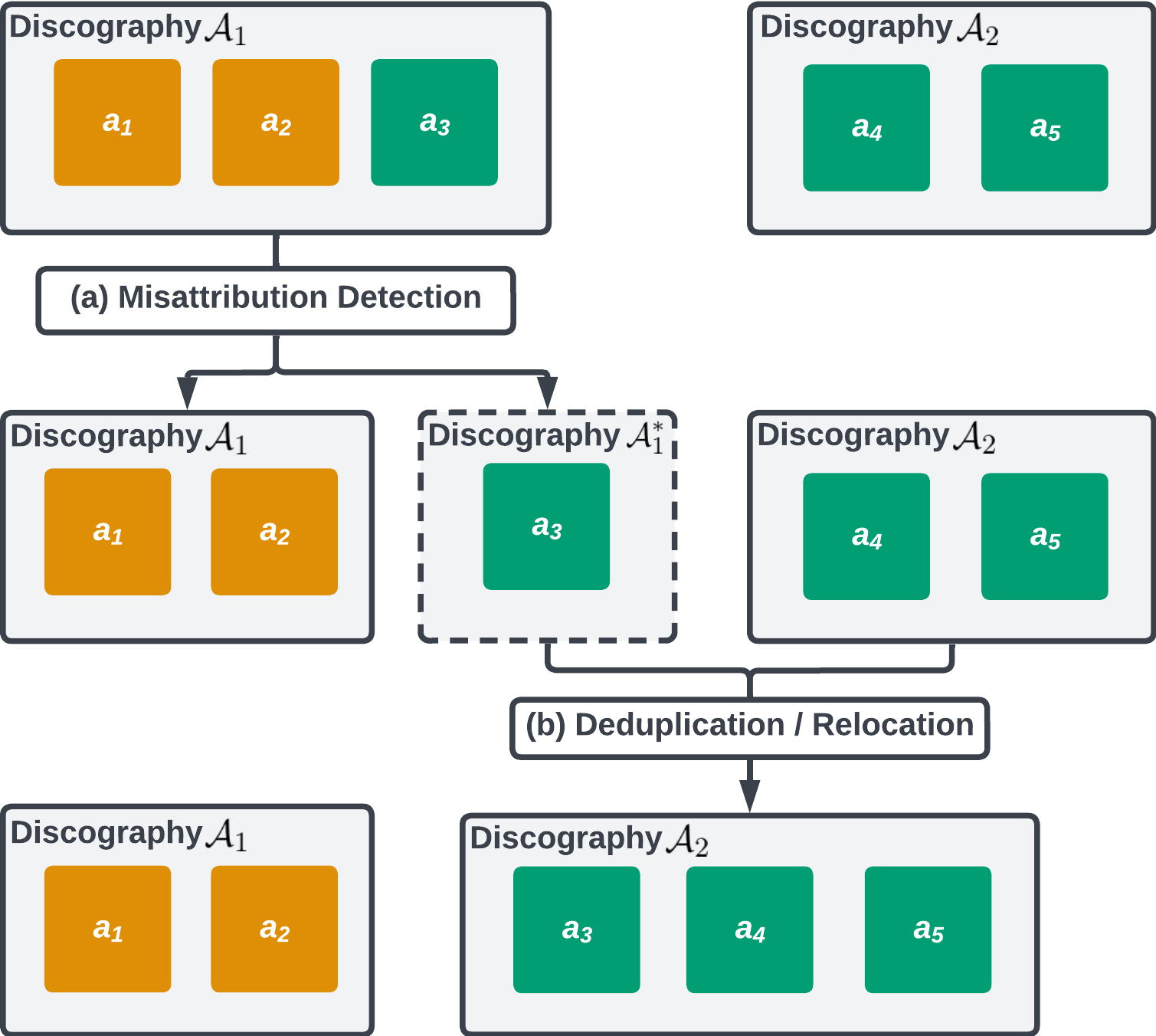
Figure 1: (a) We detect misattribution on each discography A. A misattributed release a3 is split out from A1 into sub-discography A*1. (b) We consider all (sub-)discographies for deduplication; we merge A*1 into A2, which relocates any misattributed releases into the correct discography.
The system’s objectives are to Ensure:
Correct discographies, where every release within a discography should credit the same artist.
Complete discographies, where artist’s releases should not be split across multiple discographies.
Misattribution detection
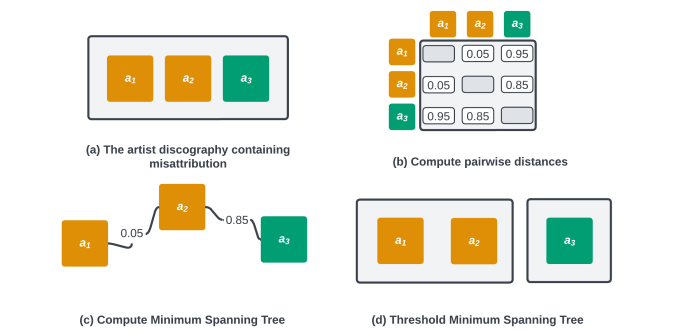
Figure 2: Steps to detect misattribution in an artist’s discography.
We trained a random forest using historical corrections of artist misattributions to determine whether two releases attributed to the same artist are really by different artists. We can think of the output of this model as a pairwise distance between all releases attributed to an artist (Figure 2b). To prevent false positives that can arise, for example, when an artist’s sound changes over time, we construct a Minimum Spanning Tree (MST) between all releases (Figure 2c). Applying a threshold to the MST to cut edges with long distances splits the discography into components that correspond to the different artists present in the discography (Figure 2d). If we are unable to cut the MST because there are no long edges, we assume that the discography contains no misattributions.
Duplicate detection
The goal of de-duplication is to merge existing discographies or sub-discographies that belong to the same artist (e.g. release a**3 in Figure 1). This process consists of two steps: (1) generating deduplication candidates through a blocking strategy, and (2) determining whether pairs of discographies belong to the same artist.
We use Elasticsearch to generate candidates; these are typically homonyms, or have similar names (e.g. Prince, Princess and Prince of Funk). We use a random forest trained on historical corrections of duplicate discographies to determine whether two discographies in the block are likely to belong to the same artist.
Experiments and evaluations
Audio and metadata feature ablations
Both the misattribution and the duplicate detection models use a combination of metadata features (such as overlap of collaborators, language of performance or music label) and audio vector representations. Our experiments show that a combination of both performs best; audio features dominate the pairwise misattribution model, and adding metadata increases average precision by 2% (Figure 3a). Interestingly, this pattern is reversed in the duplicate detection system, in which metadata features drive the performance of the system, and adding audio features increases average precision by 6% (Figure 3b).
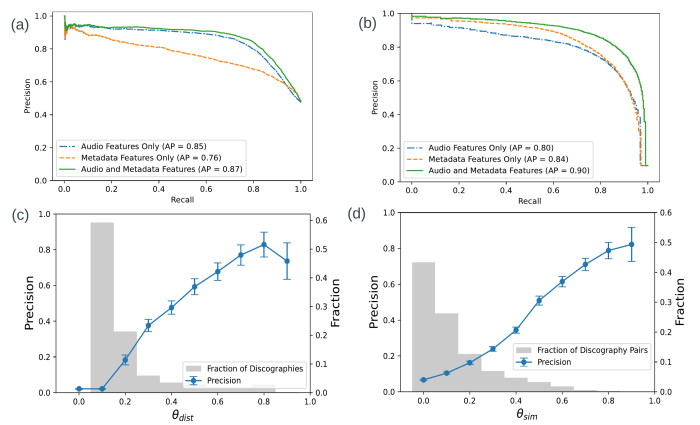
Figure 3 Evaluation: (a) - (b): Precision-Recall curves in offline experiments with combinations of audio and metadata features for misattribution detection (a) and deduplication (b). Average precision (AP) is reported in the legend for each set of features. (c) - (d): Annotation experiment results for misattribution detection (c) and deduplication (d). Precision is calculated for each threshold bucket and reweighed by the distribution of predictions shown on the second y axis.
Test driving our system with Subject Matter Experts (SMEs)
We teamed up with our annotations team and sampled ~1K examples each for misattribution and deduplication tasks. We asked SMEs to annotate examples of misattribution and duplicate discographies as by the same artist or by different artists. Figure 3 c and d shows the precision at different thresholds of the models; as the threshold goes up, the fraction of samples (and potential error detections) decreases while the precision increases. This trade-off allows SMEs to find a sweet-spot that balances precision and recall for catalog curation.
Then we ran our detection tasks in sequence (as described in Figure 1) to automatically predict suitable relocations of misattributed contect using the deduplication model. We achieve a maximum precision of 45% when both the misattribution step and deduplication (relocation) step have a high threshold (representing 17% of the sample). This means that roughly half the time, catalog curation experts don’t have to spend time looking for the right place to place a mismatched release, leading to huge time savings. The relocation task is notoriously more difficult because it inherits the uncertainty and performance of each sub-system. Additionally, a large number of misattributed releases might not belong anywhere, and will become standalone discographies because they belong to artists that are new to the catalog.
Conclusion
Although discography errors are rare, it is important to minimize them as much as possible. Systems such as the one we present in our paper that rely on ML and careful data modeling are one tool among many that platforms can use to ensure their catalog is correct, and to safeguard the experience of users and artists. The power of this system is that it can scan a large catalog efficiently, direct the attention of human reviewers to where it is most needed, and suggest corrections. These advantages make our system a key part of effective proactive catalog curation strategies.
For more detail, please check our paper: Semi-automated Music Catalog Curation Using Audio and Metadata Brian Regan, Desi Hristova, Mariano Beguerisse Díaz ISMIR 2023
SHARE THIS ARTICLE



