Modality-aware Multi-task Learning to Optimize Ad Targeting at Scale
The Challenge: An Audio-centric World
Much of our on-platform listening happens while users are occupied with something else — a typical Spotify user might be driving, working, commuting, or exercising, with Spotify playing in the background. When most people think of “online advertising,” they imagine rows of bright thumbnails or text blocks competing for attention. Spotify’s ads sit at the opposite extreme: our listeners press Play, lock the screen, and slip their device into a pocket or bag. In these moments the app is literally out of sight or backgrounded, yet the platform still must deliver the right ad at the right moment to the right listener.
That invisible context defines Spotify’s ad-tech challenge. More than 70 % of all listening happens while the app is “out-of-focus,” and click-through rates (CTR) can be roughly ten times higher when the screen is visible. At the same time, the system must rank more than seven placement types across audio, video, and display ad formats. A one-size-fits-all model skews toward the dominant audio data yet still failing to reach optimal performance on either audio impressions or the less frequent, higher-value video impressions.
To resolve this imbalance, we developed CAMoE (Cross-modal Adaptive Mixture-of-Experts), a novel modality-aware multi-task learning framework with separate heads for audio and video impressions. This architecture balances training across our two dominant modalities, while producing a calibrated ranker that increases audio CTR by 14 % and lifts video performance by 1.5 % compared to our baseline production model.
A quick tour of the ad stack
A little background on Spotify’s ad ranking system: each time an ad break is about to fire, a multi-stage ad serving pipeline gathers all campaigns that match targeting, budget, pacing and KPI constraints. The core of that pipeline is the Ad Ranker, which selects an ad for each user based on a combination of campaign optimization objectives (such as Clicks, Reach, Website Traffic or Streams), by converting every eligible impression into a predicted click, stream, view or other action probability. As is standard in the industry, this probability feeds a second-price auction to determine the final bid and winner; separate queues then dispatch audio ad pods when the app is backgrounded and video ad pods when it is foregrounded. Accurate, well-calibrated predictions are crucial at the ranking stage: over-prediction inflates bids, potentially showing the wrong ad to the wrong listener; under-prediction suppresses revenue and may increase advertiser churn.
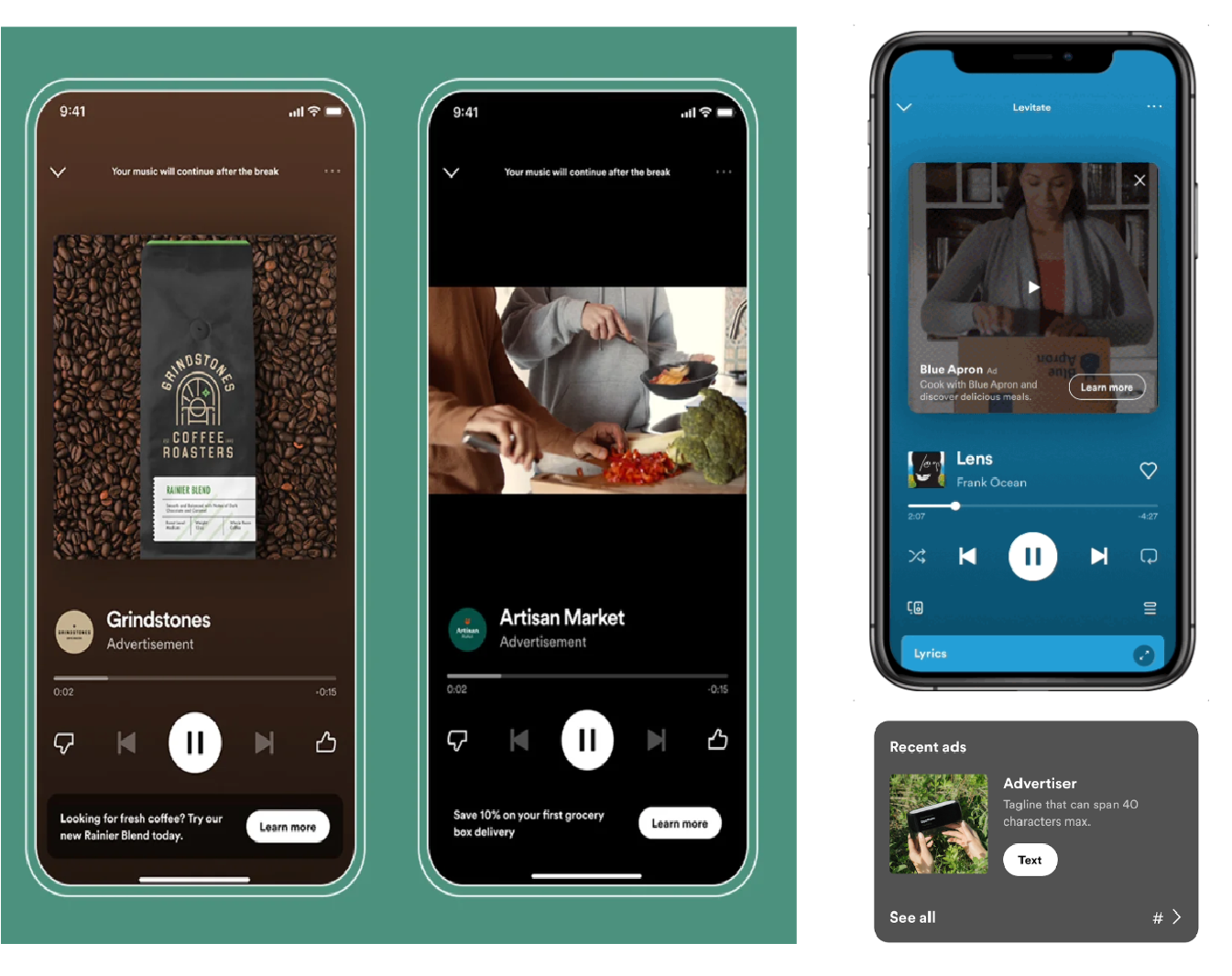
Figure 1. Ads on Spotify. Left to right: (a) An audio ad stream. (b) An unmuted video ad stream. (c) A muted embedded video ad in the Now Playing View (NPV). (d) A display ad in the NPV. An audio ad typically plays when the user is out-of-focus, while a video ad plays when a user is in-focus.
Designing CAMoE: letting each modality speak for itself
Traditional ad recommendation models, often used for more visual or uni-modal contexts, struggle to overcome these unique complexities. To address the multi-modal and imbalanced nature of our ad platform, and its resulting distinct engagement patterns, we designed a new framework for multi-modal learning: Cross-modal Adaptive Mixture-of-Experts (CAMoE). Our approach differs from standard multi-task setups in a few key ways:
Modality-specific heads: This framework builds upon the powerful Multi-gate Mixture-of-Experts (MMoE) architecture [add citation], which is designed to handle multiple related prediction tasks simultaneously using specialized subnetworks or “experts”. In our case, we split the primary CTR task into two parallel heads. One head specialises in audio-plus-display slots; the other focuses on video. Each head learns its own notion of “what looks clickable” without interference from the other modality.
Adaptive loss masking (ALM): Because audio impressions outnumber video by a wide margin, raw gradients would drown the scarcer modality. Adaptive loss masking simply drops examples that don’t belong to a given head during back-prop, guaranteeing that audio errors update only the audio tower and vice-versa. The trick slashes calibration error for video impressions while actually improving audio performance.
Deep-and-Cross experts: Inside each expert we embed a DCN-v2 block that explicitly models interactions like Friday-evening × headphones × hip-hop without hand-crafted crosses. In offline ablations, adding DCN lifted AUC-PR for Stream Video by roughly twenty percentage points over the production baseline, and made even the esoteric Embedded Music slot five times more discriminative.
While we do not enforce modality-gating for experts, we observed that experts naturally tend to specialize in a specific modality.
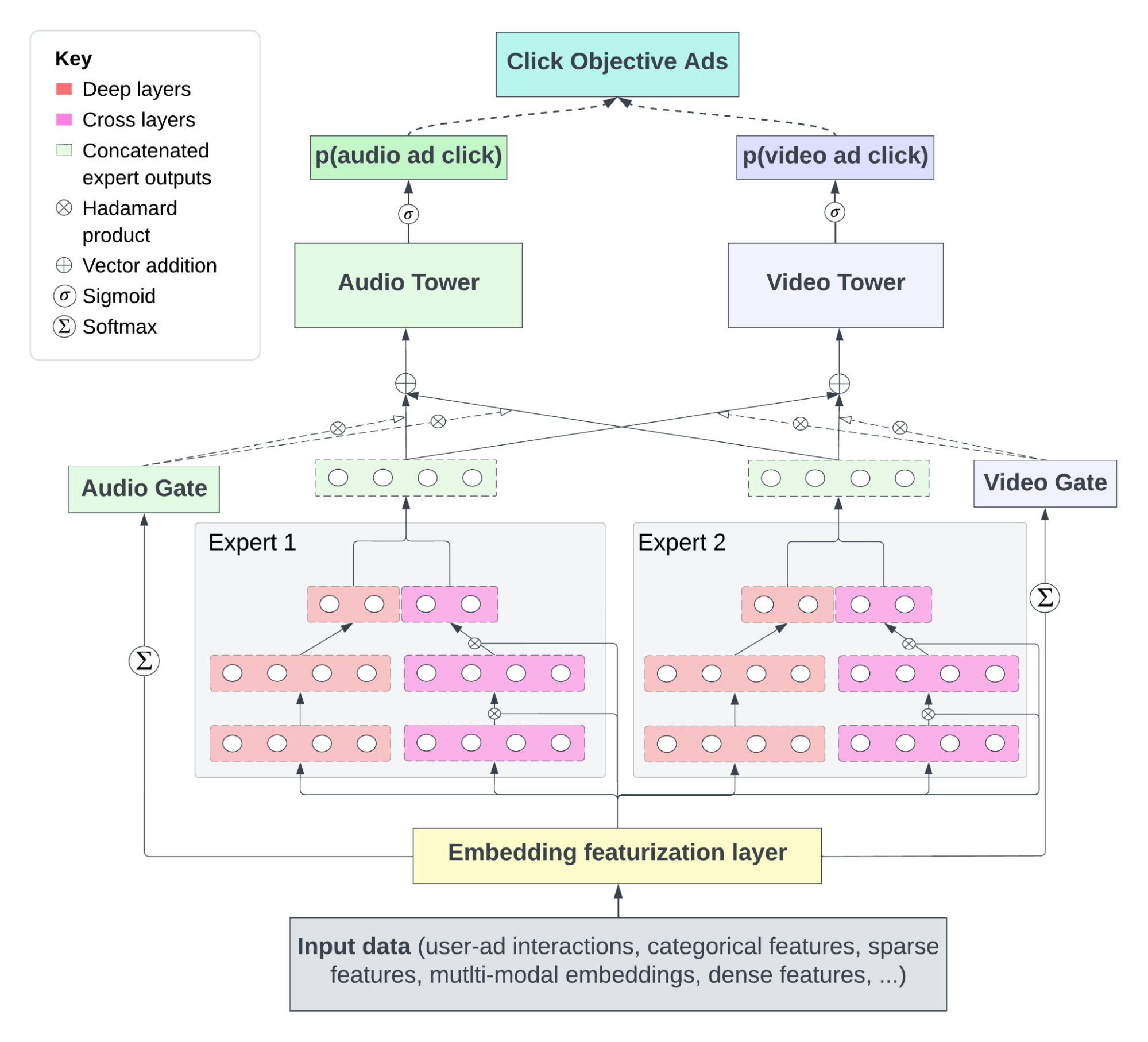
Figure 2. Architecture of CAMoE. The model starts with a shared bottom layer that embeds features, feeding into a set of “deep-and-cross experts”, and modality-specific gates which direct information to their respective towers.
Experiments & Results
We assessed CAMoE in two stages: large-scale offline experiments on historical user-ad impression logs, and a live budget-split A/B test across 20 global markets.
Offline study
Dataset and metrics: Our training dataset contained hundreds of millions of de-identified ad impressions spanning all seven placement types. We report area-under-the-precision-recall curve (AUC-PR) as the main evaluation metric and expected calibration error (ECE) to track the prediction quality, as ECE directly affects auction pricing.
Task-grouping analysis: We compared single-task (1-head), modality-based (2-head), content-based (2-head), and ad slot-based (7-head) variants of CAMoE, along with standard baselines such as DCN-v2. Splitting the click task into an audio head and a video head yielded the best balance: +20.7 % AUC-PR on Stream Video and +24.1 % on Stream Audio relative to the production baseline, while keeping calibration stable. The 7-head model improved some rare slots (e.g., Embedded Music +88 %) but lost ground on the two core formats and added significant complexity. Grouping by content type (music vs. podcast) performed better for podcast ads, but under-performed for the high-traffic audio and video streaming music slots.
Ablation studies: Removing adaptive loss masking (ALM) caused Stream Video AUC-PR to fall by 2.4 % and calibration error to more than double, likely due to the relative scarcity of video impressions. Masking restored a 20.7 % AUC-PR lift and reduced ECE by 55 %. Similarly, leveraging DCN-v2 experts demonstrated a significant boost in performance by effectively capturing feature interaction, and raised AUC-PR for every slot.
Online A/B test
A three-week budget-split A/B test across twenty markets confirmed our offline findings (p < 0.005), with significant improvements in Audio CTR, and moderate improvements in Video CTR.
Ad Slots | A/B Test | 100% Rollout | ||
|---|---|---|---|---|
eCPC Δ | CTR Δ | eCPC Δ | CTR Δ | |
Audio Ads | -8% | +10% | -4.8% | +14.5% |
Video Ads | -1.2% | +1.4% | -2.6% | +1.3% |
Key Learnings: Finding the Optimal Balance
A core part of our work was not just building a new model, but rigorously testing why our specific design choices were the most effective for our unique, audio-centric environment.
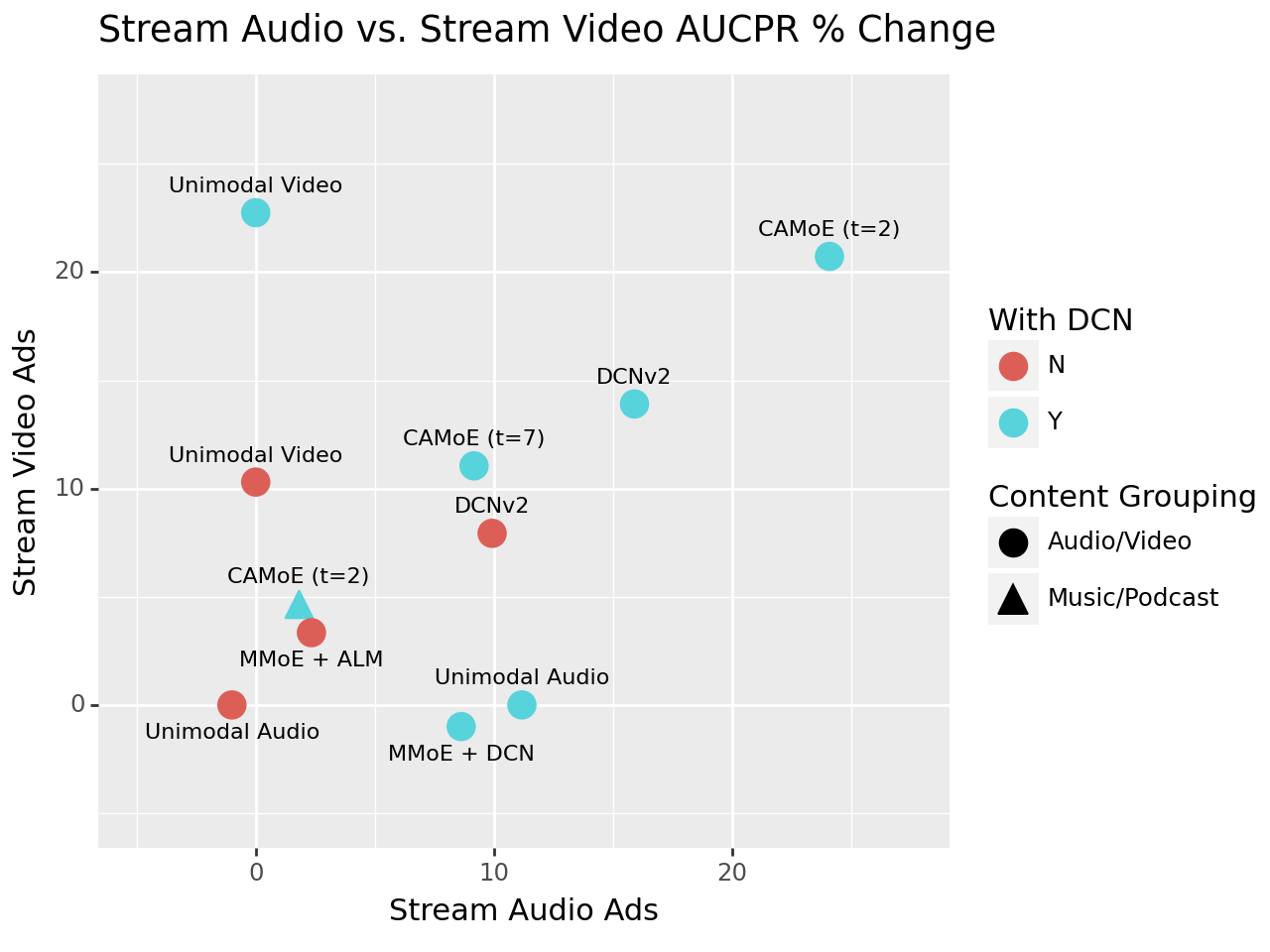
Figure 3. Analysis of Pareto Optimality for various CAMoE, multi-task and single-task configurations.
We experimented with multiple model configurations: a single-task model (1-head), a model with a task for every ad slot (7-head), and content-based grouping (music vs. podcast). Our analysis revealed that the 2-head audio-video split is near-Pareto optimal for both our largest ad formats—Stream Audio and Stream Video—compared to other setups. This means it is nearly impossible to improve performance for one ad format without hurting performance on another. This confirmed that grouping by modality (audio vs. video) =-provides the most robust and balanced performance for our entire ad ecosystem.
Where We’re Heading
CAMoE now serves 100% traffic for click-based campaigns on Spotify. Current work focuses on expert pruning and knowledge distillation to cut training costs. We are also extending the framework to optimize for other objectives—like video completions and downstream conversions—by attaching new heads without redesigning the core network. These efforts position CAMoE as a durable foundation for future ad personalization on Spotify and for any service that must rank heterogeneous media in an attention-scarce environment. For more information, please refer to our paper: An Audio-centric Multi-task Learning Framework for Streaming Ads Targeting on Spotify. Shivam Verma, Vivian Chen, Darren Mei ACM SIGKDD 2025 (Industry Track)
Acknowledgements: We’d like to thank the entire team, past and present, for their support and feedback throughout — Bharath Rangarajan, Kieran Stanley, Gordy Haupt, Nick Topping, Santiago Cassalett, Masha Westerlund, Aron Glennon, Ipsita Prakash, Sanika Phatak and Sneha Kadetodad.
SHARE THIS ARTICLE

