Prompt-to-Slate: Diffusion Models for Prompt-Conditioned Slate Generation
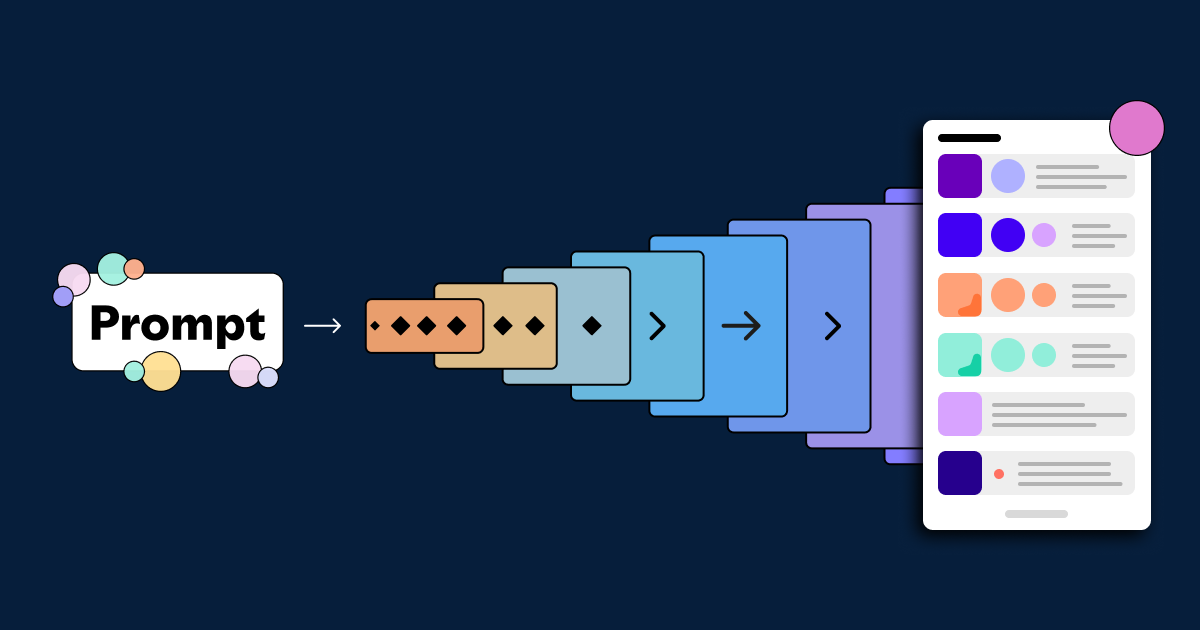
Many recommender systems present multiple items to users at once in the form of a list, or slate. This approach is common in music playlist generation, e-commerce bundles, and video recommendations. The goal is to optimize the set as a whole to maximize user satisfaction, taking into account factors such as coherence and diversity.
Traditional approaches typically evaluate each candidate item in isolation with respect to a query, rather than considering the slate as a whole. A key challenge lies in the combinatorial complexity of jointly selecting multiple items, since the number of possible combinations grows exponentially. To make the problem tractable, conventional models often assume that users engage with only a single item from the slate, a strong limitation in scenarios where items are intended to be consumed together. At the same time, there is increasing demand for systems that can flexibly generate slates from natural language prompts, often in contexts where direct user interaction data is unavailable. Our work tackles these challenges by reframing slate generation as a generative modeling problem.
Diffusion Model for Slate Generation (DMSG)
Our proposed solution is the Diffusion Model for Slate Generation (DMSG), a framework that learns the joint distribution over slates to produce coherent and diverse item sets. DMSG is composed of three main components:
Encoding Module: To apply diffusion models, which operate on continuous data, we first map discrete catalog items into a continuous latent space. Each item is converted into a vector embedding. For this work, we utilize a fixed, pre-trained encoder, which we found to improve training stability and performance. This design choice also makes the system adaptable to dynamic catalogs, as the core model does not need to be retrained when the item set changes.
Conditioning Module: The generation process is guided by a context variable, typically a natural language prompt. This textual input is encoded by a transformer-based model into a conditioning vector, which steers the diffusion process through cross-attention. In doing so, the generated slates align with the semantic intent expressed in the prompt.
Diffusion Process and Scheduling: At the core of DMSG lies the diffusion model, which learns to reverse a noising process. During training, noise is progressively added to slate embeddings, and the model is trained to predict and remove it step by step. At inference time, generation begins with a random Gaussian vector that is iteratively denoised into a clean, structured slate embedding. To ensure real-time usability, we incorporate fast sampling via DDIM, which reduces the number of inference steps while preserving quality, allowing DMSG to meet strict latency requirements.

Offline Evaluation
We evaluated DMSG through offline experiments on two tasks: music playlist generation and e-commerce bundle recommendation. Our experiments used three datasets: the Spotify Million Playlist Dataset (MPD), a collection of editorially curated playlists (Curated), and an Amazon-based bundle recommendation dataset (Bundle). We compared DMSG against several baselines, including Popularity, Prompt2Vec, BM25, and a sequence-to-sequence (S2S) model.
Relevance. To evaluate relevance, we employed standard ranking metrics along with similarity-aware variants (NDCGSim, MAPSim), which award partial credit to recommended items that are semantically similar, but not identical, to those in the ground-truth slate. Across nearly all metrics, DMSG outperformed the baselines. On the Curated dataset in particular, it delivered a +17% gain in NDCGSim and a +12.9% gain in MAPSim over the strongest baseline, BM25.

Diversity and Freshness: We assessed diversity along two dimensions: the ability to surface less popular items and the capacity to generate varied slates for the same prompt. Unlike retrieval-based models such as BM25, DMSG more frequently recommends less popular items, enhancing catalog exposure and user discovery. Moreover, its stochastic generation process naturally promotes freshness. When prompted multiple times with the same input, DMSG consistently produced novel, non-repeated items across slates, while maintaining high quality, achieving an average BERTScore of about 0.8.

Online Experiments
To validate our approach in a real-world setting, we ran a two-week live A/B test within a production music playlist generation system. The experiment included 1 million users across 4.8 million sessions. In the control group, users were served recommendations from the existing production model, a personalized retrieval-based system. In contrast, the treatment group received slates generated by DMSG, which, notably, did not rely on explicit personalization.
The live experiment demonstrated clear benefits across engagement, diversity, and efficiency:
User Engagement: DMSG drove a +6.8% uplift in stream curations (e.g., adding tracks to personal playlists) and an even stronger +10.5% uplift in tracks added to “Liked Songs.” These gains were most pronounced among existing, habitual users.
Content Freshness: Compared to the control, DMSG delivered significantly more diverse recommendations, with a -13.4% reduction in repeated tracks served to the same user.
Performance: The system proved highly efficient, achieving a P99 latency of 150ms, versus 500ms for the control.
Expected Trade-offs: As expected, prioritizing freshness over explicit personalization led to modest downsides: a -5.6% decrease in listening duration and a +3% increase in skip rate. These effects reflect the intended design of DMSG, which emphasizes discovery by promoting fresh content rather than tailoring heavily to past preferences.

Conclusion and Future Work
This work shows that diffusion-based prompt-driven slate generation is a viable approach for producing structured, high-quality recommendations at scale. The framework leverages generative modeling to create coherent, diverse slates while remaining efficient, low-latency, and able to balance freshness with relevance.
Looking ahead, several extensions are possible. One direction is incorporating richer metadata into the generation process to better align prompts with the resulting slates. Another is exploring prompt reformulation techniques to provide finer-grained control over outputs. Beyond text, the framework can also condition on alternative signals, such as seed catalog items or user interaction patterns, broadening its applicability across recommendation scenarios.
For more information, please refer to our paper: Prompt-to-Slate: Diffusion Models for Prompt-Conditioned Slate Generation Federico Tomasi, Francesco Fabbri, Justin Carter, Elias Kalomiris, Mounia Lalmas, Zhenwen Dai RecSys 2025
SHARE THIS ARTICLE

