Multi-Task Learning of Graph-based Inductive Representations of Music Content
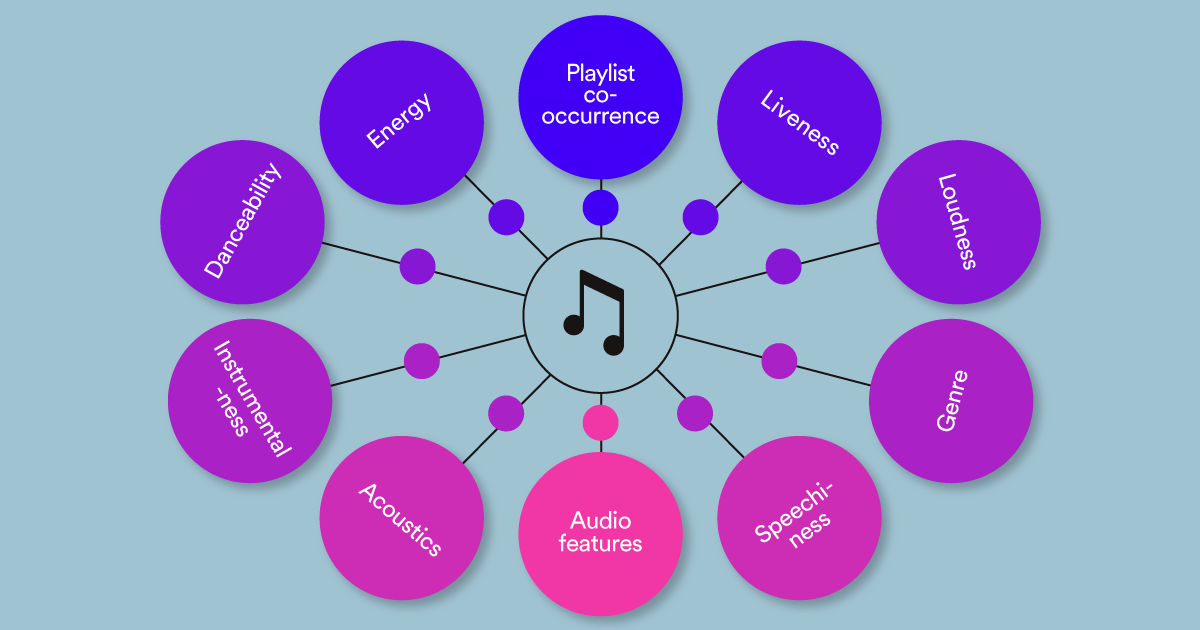
Personalization services at Spotify rely on learning meaningful representations of tracks and users to surface apt recommendations to users in a number of different use cases. When learning track representations, one can leverage various types of heterogeneous information encoded in music data to benefit downstream recommendation tasks:
organizational information: tracks organized into playlists;
content information: audio and acoustic features extracted from tracks; and
musical stylistics: musical domain characteristics like music genres.
We developed MUSIG, a multi-task formulation of graph representation learning to learn track representations based on both content features and structural graph neighborhoods. Our model is trained on multiple tasks (playlist co-occurrence, acoustic similarity and genre prediction), which enables the generalizability of the learned embeddings on downstream tasks.
We evaluated MUSIG on a music dataset representing tracks and playlists from Spotify, from a collection of over 95K playlists. Our experiments showed that our graph-based approach has numerous advantages:
Allows us to aggregate graph structure and node features, encoding two sources of complementary information;
Enables specifying different types of relations or nodes, to allow for embeddings which generalize across multiple downstream tasks; and
Is inherently inductive, thereby allowing to obtain representations for new tracks without the need for model retraining.
We empirically validated our approach against the state of the art for representation learning on musical data. Our results show the benefit of aggregating both organizational and content information to learn track representations that are used for downstream tasks.
Methodology
We work with data consisting of track and playlist information; tracks are organized into playlists, which in turn provide information on how users organize their music. We represent playlist-track information as a graph and create a weighted homogeneous graph containing all tracks in our dataset, where the weight of an edge represents the number of distinct playlists in which the connected tracks co-appear. Our graph contains 5.2M edges and 15.9K nodes, from a collection of 95K playlists.
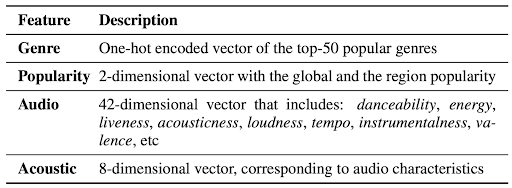
Following the approach outlined in [1], we extract various content features from the music recording of the track, including acousticness, danceability, energy, instrumentalness, liveness, loudness, speechiness, valence and tempo, which we refer to as audio features (see table below). Furthermore, we train a deep neural model on the music recording of each track (via 30-second windows) for a binary classification task of playlist co-occurrence and we use the last layer projected to 8 dimensions as the acoustic features of the track.
To aggregate information from across the organizational structure, content and musical style, we perform a multi-task supervision of representation learning modules, which consist of aggregator functions operating on the neighborhood of a node. This enables our model to learn parameters of the functions based on feedback from multiple, complementary tasks. Specifically, the algorithmic computations performed by MUSIG are divided into two key steps:
Neighborhood Aggregator Step, which generates embeddings by aggregating information from different nodes in multiple hops away from a given node (based on search depth).
Multi-Task Supervision Step, which trains the parameters of the aggregation functions by jointly predicting multiple tasks, and back-propagates the combined losses to the aggregator function parameters.
An overview of MUSIG training is depicted in the figure below, where we have, for illustration purposes, three downstream tasks, y1,y2, and y3.
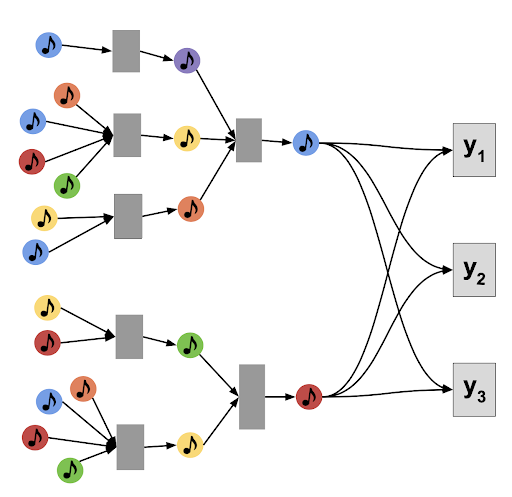
Our paper shows how we iteratively aggregate the neighbors for each node, and such learned embeddings are then evaluated on each of the three tasks (y1,y2,y3).
Results
We compare the proposed MUSIG with representative models from the three different classes of representation learning approaches: collaborative filtering, Word2Vec-based models (Track2Vec, leveraging track co-occurrence in playlists), Node2Vec (leveraging graph structure) and GraphSAGE (leveraging graph structure and content features).
Since MUSIG model affords multiple supervision, it is trained on genre prediction and audio/acoustic feature similarity tasks in addition to the playlist co-occurrence task. We modulated the balance between the three tasks empirically, by evaluating different weights for the task which emphasize more or less one particular loss function.
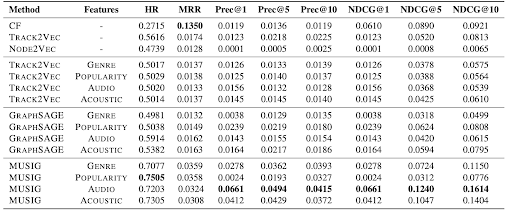
We compare all representation learning approaches to ours (MUSIG), on the playlist completion task (see table above), using 50% of the playlist as seedlist. The results show the benefit of using MUSIG trained on the Music Graph using the multi-task training and including the POPULARITY in the node attributes, which outperforms all other models.
The table also reports the importance of leveraging content features while learning embeddings. We selected the best performing track (TRACK2VEC) and node embedding (GRAPHSAGE) models, and we evaluated the performance of these models and MUSIG using different groups of features node attributes (GENRE, POPULARITY, AUDIO, ACOUSTIC). For fair comparison, in TRACK2VEC we used aggregations of features and track embeddings. We observe that TRACK2VEC achieves best performance when trained without the content features, which was expected since the model is designed to leverage only organization information.
MUSIG improves the hit-rate score of the best existing model by 27%. This is an important indicator that embeddings generated by optimizing on multiple tasks are able to significantly improve the performance of the downstream task of playlist completion. Furthermore, this indicates that imparting the representations to perform well on genre classification and acoustic/audio distance similarity tasks enriches them further, improving the performance. We leave for future work further validation of other tasks for training, , and understanding the trade-off between multi-task supervision and generalizability of the learnt representations on different downstream tasks.
Summary
We proposed MUSIG, a multi-task graph-based learning model for music recommendation. Our method learns the track representations based on content features and structural graph neighborhoods, while the multi-task training is aggregating multiple functions and learning representations based on supervision from multiple training tasks. Empirical results demonstrate the benefits of our method, wherein we show the value of the multi-task over single-task learning. Furthermore, we show that extracting content features (such as audio or acoustic) improves the performance in existing methods, achieving the best improvements when those features are used in the multi-task setting.
More information can be found in our paper: Antonia Saravanou, Federico Tomasi, Rishabh Mehrotra & Mounia Lalmas. Multi-Task Learning of Graph-based Inductive Representations of Music Content. ISMIR 2021
References
[1] T. Bertin-Mahieux, D. P. Ellis, B. Whitman, and P. Lamere, “The million song dataset,” 2011.
SHARE THIS ARTICLE

