The Contribution of Lyrics and Acoustics to Collaborative Understanding of Mood

Song lyrics make an important contribution to the musical experience, providing us with rich stories and messages that artists want to convey through their music. They influence the perceived mood of a song, alongside the acoustic contents (including the rhythm, harmony, and melody) of the song. In some cases, these two components - lyrics and acoustics - work together to establish a cohesive mood; and in others, each component provides its own contribution to the overall mood of the song.
Let's imagine an example of a song, where its lyrics talk about the end of a relationship, and suggest moods related to sadness, longing and heartbreak, while at the same time, its acoustics have a familiar chord progression, and somewhat high tempo, suggesting calm and upbeat moods. This scenario is not an exception, in fact, a recent analysis of the lyrics and acoustics of popular music identifies a trend where song lyrics have been getting sadder in the last three decades, while at the same time, the songs also become more “danceable” and “relaxed”.
In our recent ICWSM paper, we set out to investigate the association between song lyrics and mood descriptors, i.e. the terms that describe affectual qualities of a song. To this end, we conduct a data driven analysis using state-of-the-art machine learning (ML), and natural language processing (NLP) techniques, to compare how lyrics contribute to the understanding of mood, as defined collaboratively by the playlisting behavior of Spotify users.
This work is motivated by our desire to improve the Spotify experience, specifically in relation to music search, discovery and recommendations. From the search and discovery perspective, we want to enable search based on mood descriptors in the Spotify app, for example by allowing users to search for “happy songs”. Additionally, from the recommendations side, we want to be able to recommend new songs to users that provide similar sets of moods users might already like.
At the same time, this work is driven by the research question, “How much do the lyrics and acoustics of a song each contribute to understanding of the song’s mood?”.
Data
In this work we used a set of just under 1 million songs.
The mood descriptors for this set of songs included terms like “chill”, “sad”, “happy”, “love”, and “exciting”. They are not limited to a specific part-of-speech, covering adjectives (“sad”, “somber”, etc), nouns (“motivation”, “love”, etc.) and verbs (“reminisce”, “fantasize”, etc.).
The association between a song and a mood descriptor was calculated using collaborative data, by “wisdom of the crowd”. More specifically, these relationships were derived from Spotify playlists’ titles and descriptions, by measuring the co-occurrence of a given song in a playlist, and the target mood descriptor in its title or description.
Experiments and results
We tackled a number of experiments aimed at studying the contribution of lyrics and acoustics to the mood of a song. In this blog post we summarize some of the most relevant ones we performed in the scope of this problem, and for more details, we invite you to read the full paper linked at the end of this post.
To understand the contribution of lyrics, acoustics, or combination of lyrics and acoustics to the mood of a song, we used several ML classifiers to predict mood descriptors, each trained on features extracted from different modalities: acoustic, lyrics, and hybrid. Then, we performed an analysis of the different models, and compared their results.
Lyrics and mood descriptors: We start by studying the relationship between song lyrics and mood descriptors. To this end, we train several models that leverage song lyrics alone, and not audio. These models can be broadly categorized into two distinct learning paradigms: zero-shot learning, and fine-tuned models. For the former, we take advantage of models trained on either natural language inference (NLI), or next sentence prediction (NSP) tasks, to represent the lyrics and predict their relationship to mood descriptors. For the latter, we use either a bag-of-words (BoW) model, or features extracted from transformer-based models to represent the lyrics, before modeling their relationship to mood descriptors.
Acoustics and mood descriptors: To address modeling the relationship between the acoustics only of songs and moods, we train one model on features extracted from the Spotify API, which captures acoustic information that describes audio, and songs in particular, in terms of several acoustic characteristics such as beat strength, danceability, energy, and others. These features were then modeled to predict the association of a song’s audio to a mood.
Lyrics, acoustics and mood descriptors: Finally, we explore two hybrid approaches, which capture information from both the lyrics and the acoustics of songs to predict their association with any given mood. One represents the song (lyrics, and acoustics) by concatenating the bag of words representation of the lyrics and the Spotify API acoustic features (‘Hybrid-BoW’).
The other creates a hybrid representation of a song based on the features obtained by a fine tuned transformer model, and the hidden representation of the same acoustic features as the Hybrid-BoW model, obtained by feeding them into a multilayer perceptron (MLP) (‘Hybrid-NLI’). This hybrid representation is passed into a classification head to generate predictions. The image below shows a diagram with the architecture of the Hybrid-NLI model.
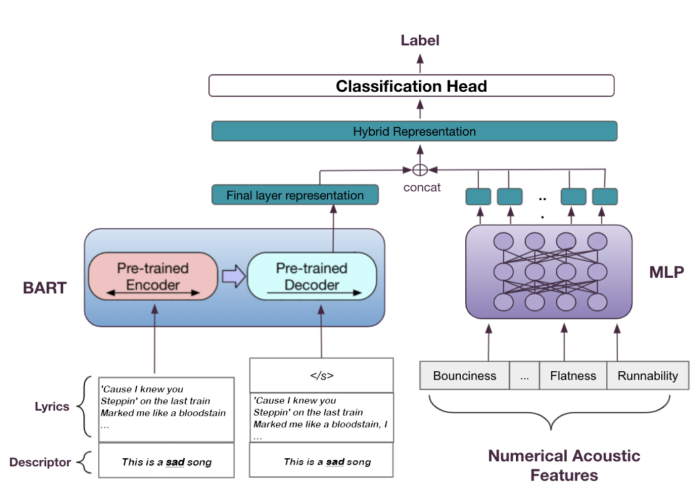
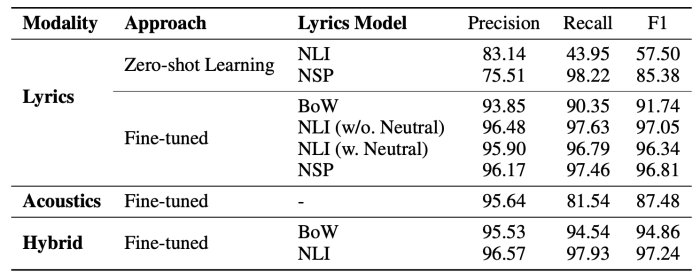
After training all the models - based on acoustic, lyrics or hybrid features - we test them on our Spotify dataset. The performance of all the models is reported in precision, recall and F1-score, in the table below.
Conclusions
With these experiments, we observed, based on the best performing model for each modality, that lyrics play a bigger role than acoustics to establish the mood of a song. At the same time, by looking at the performance of the hybrid models, particularly the Hybrid-NLI, we saw that by combining information extracted from the two modalities - lyrics and acoustics - we can best predict the relationship between a song and a given mood. This result strengthened our initial hypothesis that lyrics and acoustics work together, either in harmony or by complementing each other to establish the mood of a song.
Overall, the collection of results obtained from these experiments are encouraging, in that they show us that it is possible to learn patterns that correlate songs to mood descriptors - a highly personal and subjective task.
We further broke down the problem of finding patterns between songs and moods, and compared the performance of our models at predicting different moods, observing that some are much more ambiguous than others. We also compared the performance of our model to that of human annotators. These and other experiments can be found in our paper linked at the end of this post.
Summary
In this work we have looked at the association between song lyrics and mood descriptors through a data-driven analysis of Spotify playlists. We took advantage of state-of-the-art natural language processing models based on transformers to learn the association between song lyrics and mood descriptors, based on the co-occurrence of mood descriptors and songs in Spotify playlists. We’ve also decoupled the contribution of song acoustics and lyrics to establish a song’s mood, and observed that the relative importance of lyrics for mood prediction in comparison with acoustics depends on the specific mood. These, and a few more experiments, can be found in our paper here:
The Contribution of Lyrics and Acoustics to Collaborative Understanding of Mood
Shahrzad Naseri, Sravana Reddy, Joana Correia, Jussi Karlgren, Rosie Jones
ICWSM 2022
SHARE THIS ARTICLE



