Stochastic Variational Inference for Dynamic Correlated Topic Models

Topic models are useful tools for the statistical analysis of data as well as learning a compact representation of co-occurring units (such as words in documents) as coherent topics. However, in many applications, topics evolve over time, as well as their relationship with other topics. For instance, in the machine learning literature, the correlation between the topics “stochastic gradient descent” and “variational inference” increased in the last few years due to advances in stochastic variational inference methods. Our contribution is a topic model that is able to capture the correlation between topics associated with each document, the evolution of topic correlation, and word co-occurrence over time.
This is important when considering news articles (or generally textual documents), which may include similar topics and evolution of such through time. This can also be applied in domains other than text. In music, for example, applying our dynamic topic model to music listening data could help discover the temporal dynamics of users’ listening behaviours, which in turn reveals an important aspect of users’ preference. This can help us understand what type of content a user likes to listen to at a specific time.
Dynamic correlated topic model (DCTM)
In topic modelling, a topic is a probability distribution of the words appearing in a document. It is easy to imagine that, given a document on a topic such as machine learning, some words are more likely to appear than others in the document. Each document is represented as a mixture of multiple topics. DCTM captures the correlation between co-occurring topics in a document and the evolution of the topics and their proportions over time.
We consider three dynamic components: the probability of topics to appear (µ), the topic correlation (∑) and topic-word association (β). Each document is associated with a possibly unique time point. However, as the components are continuous processes, we can condition them on the time of the document under analysis. We consider Gaussian and Wishart processes, and rely on variational inference (with mini-batch training) to scale the inference to arbitrarily large data sets efficiently.
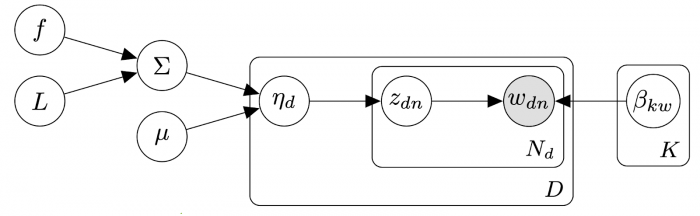
The graphical model for DCTM
Based on the values of the components, the probability of a word (w) in the document is driven by the probability of topics appearing at that particular time point, and the probability of the words associated with a chosen topic. As usual in topic modelling, we consider words to be independent of each other, and each word to be generated by a possibly different topic.
We compared our DCTM to state-of-the-art topic models, both static (LDA, ProdLDA and CTM) and dynamic (FastDTM and gDTM), using three different datasets (State of the union addresses, department of justice press releases, and NeurIPS conference papers), each with different characteristics (e.g. in the number of documents per time and the time span). LDA, ProdLDA, FastDTM and gDTM model independent topics. CTM is the only baseline model that considers correlated topics, as our DCTM. The table below shows the average per-word perplexity on the test set per each dataset. The perplexity is measured as an exponent of the average negative ELBO per word (the lower, the better). DCTM outperforms the baselines on all datasets. These results show that DCTM is able to balance temporal dynamics and topic correlations.

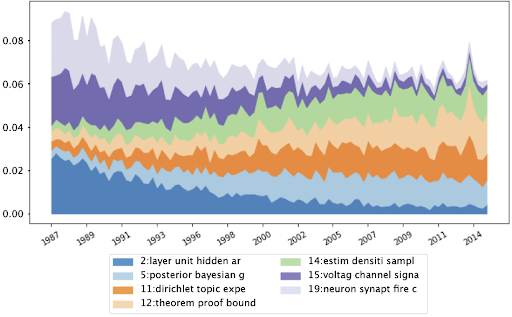
We qualitatively analyse the results from the DCTM model on the NeurIPS dataset (30 years time span, with an average of 34 papers per year). We show a sample of the probability of the topics appearing in papers published at NeurIPS over several years in the figure below. Neuroscience topics (15 and 19 in the figure) decreased over time, as papers of this field were less present in the conference. Indeed, NeuRIPS started with many submissions on neuroscience, and then evolved to include a wider range of machine learning areas. Theoretical (topic 12) and topic modelling (topic 11) publications increased over time.
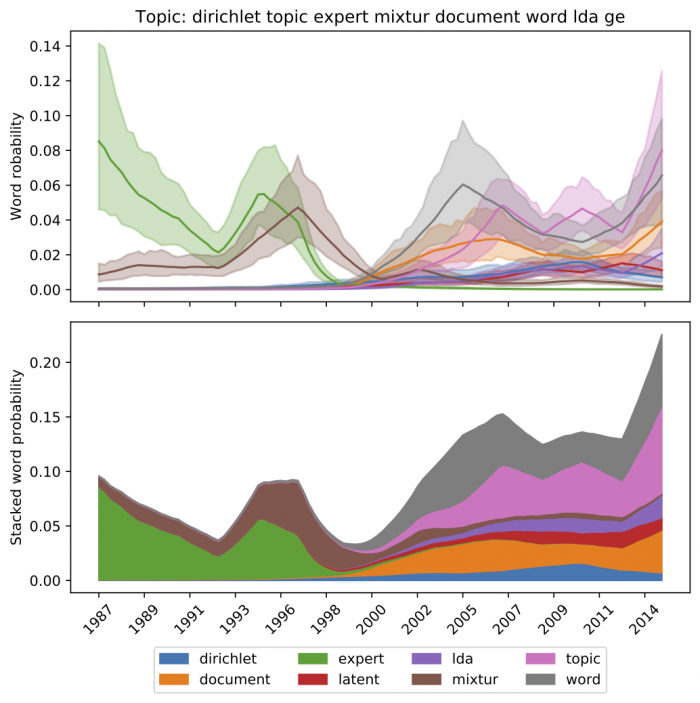
DCTM also allows us to zoom in into a single topic, and understand the evolution of the words associated with a particular topic. The figure below shows the evolution of the words associated with topic modeling in the research literature. After its introduction in2003, topic modeling has been referred to using words such as LDA, topic, and document, while previously it was associated with the words expert and mixture.
Some final words
Our dynamic correlated topic model incorporates temporal dynamics for each of the word-topic distribution, topic proportions, and topic correlations. Future work could look into extending the model to use more sophisticated time-series models, such as forecasting and state-space models to improve its capability in long-term forecasting.
For more information please check out our paper [here].
SHARE THIS ARTICLE

