Query Understanding for Surfacing Long-Tail Music Content

Search plays an important role in surfacing content in front of users. Typical of most search and recommender systems, there often exists content that is rarely surfaced to the users, the so-called long-tail content. Given the important role search plays in surfacing content, investigating ways to provide exposure to long-tail content would go a long way in developing a healthy and sustainable platform, both from the content side (e.g. by exposing content) and also the user side (e.g., by facilitating discovery). We consider two illustrative examples of content where surfacing long-tail content may work: Casual Music and Niche Genres. We propose query understanding techniques to identify non-focused search queries with broad intents, where users are generally more open to non-specific recommendations. Identifying such non-focused queries provides opportunities to surface results composed of long-tail content.
Approach
Recent research on broad-intent queries and user mindset analysis distinguishes between focused and non-focused queries [1]. Focused queries relate to a specific information need, e.g., "Katy Perry fireworks". Non-focused queries represent a more broad and open ended information need, where users have a seed of an idea in mind and are generally more open to non-specific recommendations, e.g., "relaxing music" (an example of casual music). We want to detect non-focused queries, which we believe are candidate search queries for which the ranking algorithm could surface long-tail content to users while satisfying their search needs.
An intuitive approach could be to check existing results associated with queries, and check for which queries the users are already consuming long-tail content. However, such content is by definition surfaced very rarely, hence the simple inspection of results for existing queries is largely ineffective. We therefore need a different approach. We propose to look at query features to learn the suitability of a query to include long-tail content through different machine learning models. To bootstrap, we consider a subset of queries that have been marked suitable to include long-tail content or not by domain experts. Then, we show how we can employ machine learning models that are able to generalise from a small set of labeled queries to the general query space.
Query features
We identify three classes of features derived from query characteristics and user interactions:
Standalone features: these include surface-level information from the queries alone; e.g. number of long-tail content displayed to users, number of those consumed by the users for a particular query.
Reference dependent features: these are conditioned on gold standard (reference) queries that already included long-tail music content in their results, and consumed by users; e.g. overlap in displayed / clicked results, query embedding distance, pronunciation distance, knowledge graph distance.
Interaction features: quantifying the generality of a query by understanding how users interact with its results; e.g. entropy.
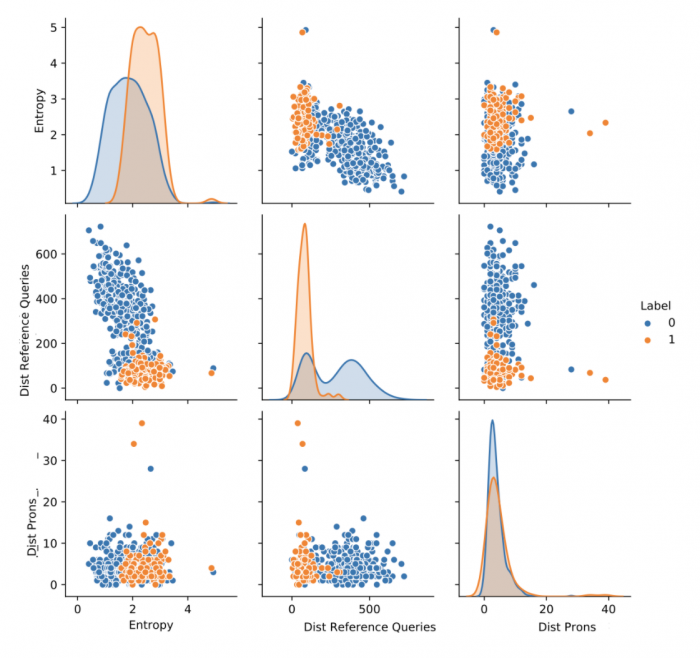
Figure 1: Pairplot between the most discriminative features on Casual Music.
Figure 1 shows the distribution of some features on a dataset of labeled queries, i.e., for which we have the labels associated with the queries (class 0: focused queries, candidate query unsuitable for long-tail content; class 1: non-focused queries, candidate query suitable to include long-tail content). The features are
Entropy (based on the position of the content consumed in search; interaction feature),
Dist Reference Queries (the average embedding distance between each query and reference queries; reference dependent feature), and
Dist Prons (pronunciation distance to reference queries; reference dependent feature).
We see that Dist Reference Queries almost displays a bi-modal distribution that discriminates between the target classes. The feature values that best identify class 1 are concentrated on the left part of the plot: this means that a single threshold on this feature could potentially discriminate the majority of the queries. Further, we observe that the click-entropy of a query is well correlated with long-tail content due to the inherent nature of non-focused queries: non-focused queries lead to a higher chance for the user to consume a wider range of results proposed by the search system. The combination of the features yield even better correlation with the target label.
Overall, our analysis showed that these classes of query features are good candidates to use in machine learning methods aiming at identifying queries for which long-tail content can be surfaced in the search results.
Learning Models
We devised thresholding-based and machine learning models for the task of identifying non-focused queries. Threshold-based modelsaim at predicting the output based on an evolving threshold for single or combination of features. The combination of features can also be automatically found through the use of a decision tree classifier. Machine learning modelsinclude two main approaches: random forest (an ensemble method built from a multitude of decision trees) and neural network (comprising two dense layers with dropout). Finally*,* we also combine the best performing models into an ensemble, a voting mechanism that aims at higher recall if any of the single models have predicted a query to be non-focused.Indeed, as the goal is to increase the number of queries for which to include more long-tail content, a higher recall for class 1 (non-focused queries) is preferable. The trade-off is in particular with respect to the precision for class 0 (focused queries), as a drop in precision for class 0 may result in long-tail content surfaced in non-suitable queries, potentially resulting in a loss of user satisfaction. Overall, we found that trained models give the best accuracy, and overall a better balance between the performance on both classes. We used such methods in an online evaluation through A/B tests.
Online evaluation
We conducted live A/B tests, where we trained two alternative rankers by using features that indicate whether a candidate result belongs to the Niche Genre (or Causal Music) content group or not, our two use cases to surface long-tail music content. We then boosted weights of those features relative to other default features in the ranker. Ideally, the optimal approach would increase the number of queries for which we were able to surface results from long-tail content, while minimizing user dissatisfaction. We identify queries for which the treatment ranker surfaced a search result from Niche Genres (or Causal Music), and the control ranker did not. We logged whether the user interacted with the newly surfaced result from the Niche Genre (or Causal Music) content group, and used that information to assign satisfaction labels to the query.We use two metrics to evaluate our results: gain in exposure (number of non-focused queries identified by the method; the higher, the better), and loss in satisfaction (proportion of non-focused queries where users did not stream the surfaced content; the lower, the better). An ideal approach would maximize gain in exposure while minimizing loss in satisfaction.
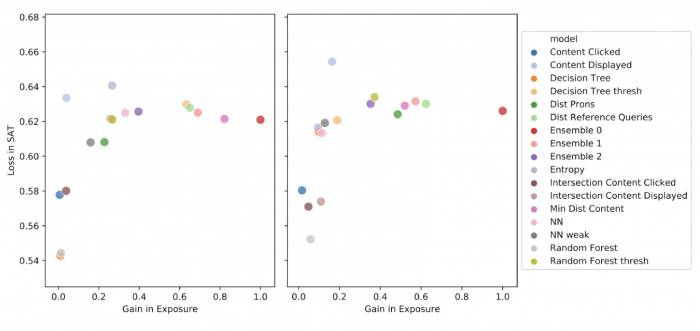
Figure 2: Gain in exposure vs Loss in satisfaction results from live A/B test, for Casual Music content group (Left) and Niche Genres content group (Right).
Figure 2 reports the results. A perfect method would be in the bottom right part of the plot (high gain in exposure, low loss in satisfaction). However, we can make trade-off based decisions based on these results. We observe that some methods (e.g., threshold-based models like entropy) fare poorly for the Niche Genre group, since they suffer from loss in satisfaction without offering much gain in exposure. Some methods are fairly conservative (e.g. decision tree classifier and intersection of displayed Content), which help platforms stay conservative and not risk any loss in satisfaction but reduce the number of exposures. Finally, the ensemble model (Ensemble-0, red dot) provides the best trade-off: significant gains in exposure, with comparable loss in satisfaction.
Our results show the efficacy of the proposed features in conjunction with a wide range of machine learning models. The features that we proposed are easily computable for all of the search queries, even for those that do not include long-term content.
Conclusion
We proposed a framework to develop query understanding techniques to identify potential non-focused search queries on Spotify. Identifying such non-focused queries provides opportunities to surface long-tail music content, while maintaining user satisfaction.
For further information, please refer to our paper: Query Understanding for Surfacing Under-served Music Content Federico Tomasi, Rishabh Mehrotra, Aasish Pappu, Judith Bütepage, Brian Brost, Hugo Galvão and Mounia Lalmas CIKM 2020
References
[1] Li, Ang, Jennifer Thom, Praveen Chandar, Christine Hosey, Brian St Thomas, and Jean Garcia-Gathright. “Search mindsets: Understanding focused and non-focused information seeking in music search.” The World Wide Web Conference, 2019.
SHARE THIS ARTICLE
