Personalizing Audiobooks and Podcasts with graph-based models

Spotify's catalog includes millions of music tracks and podcasts and has recently expanded to Audiobooks. Personalizing this content to users requires our algorithms to “understand” user preferences as well as content relationships across all content types. We argue that this level of algorithmic understanding can be efficiently achieved with graph-based machine learning, in a way that remains scalable for production. In May 2024, we present two papers around this topic at the Web Conference.
In the first paper, we outline our research giving rise to a graph-based approach for modeling Audiobooks together with podcast and music signals. This resulted in a system which was productionized, successfully overcoming the cold-start problem related to the lack of historical Audiobook consumption data. In the second paper, we take the idea one step further to equip the system with foundational modeling capabilities, that is, allowing it to distill knowledge from multiple sources; after adaptation, this distilled knowledge (representation) can be used for multiple downstream tasks related to the personalization of multiple content types, including podcasts.
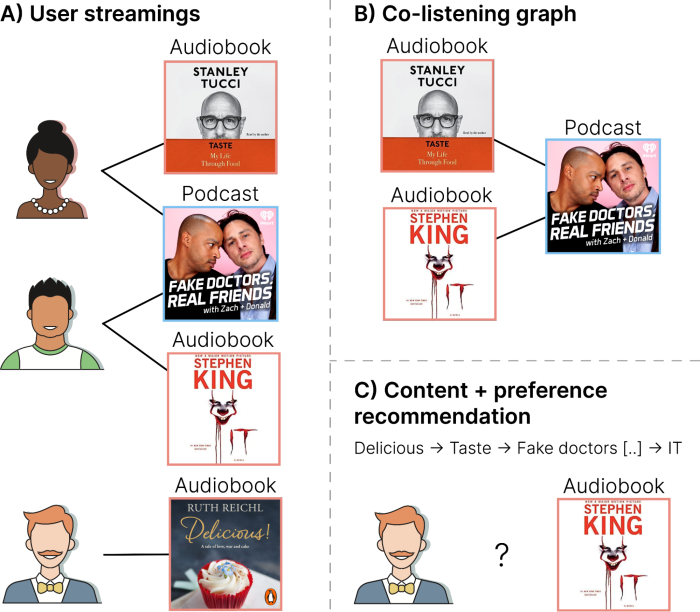
Figure 1: A) Our users’ consumption patterns, which involve audiobooks and podcasts; B) We build a co-listening graph with nodes representing audiobooks or podcasts, and edges connecting nodes whenever at least one user streams both; C) Audiobook IT gets recommended because 2T-HGNN per- forms non-trivial recommendations using 2-hop distant pat- terns. Delicious is similar to Taste. Taste is co-listened with Fake Doctors, which is co-listened with IT.
Graph-based personalization for Audiobooks
Let us consider recommendation as a particular flavor of personalization. The task is to train an algorithm that recommends Audiobooks to users. During the development of the algorithm, in 2023, Audiobooks was a new content type which lacked user interactions to be used as training data. Thus, it was natural to seek to leverage the user's known historical preferences for music and podcasts, as well as content similarities among Audiobooks and podcasts. For example, an audiobook about medieval history has some similarity with a thematically similar podcast. Representing audiobooks and podcasts as nodes in a graph allows us to achieve the above because: (a) node connectivity is based on co-listening, i.e. audiobook A and podcast P are connected if at least one user has listened to both, thus capturing cross-content type interaction information; and (b) each audiobook and podcast node is associated with a set of features derived from Large Language Models (LLMs) applied on their title and description; content similarities are captured in this way.
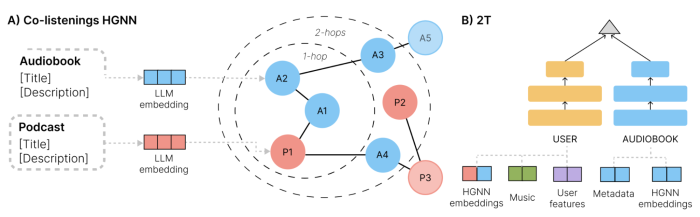
Figure 2: The overall system: Large Language Models (LLMs) perform content understanding from Audiobooks (A) and Podcasts (P). These are used as node features when training the Graph Neural Network on a co-listening graph. A two-tower model (2T) consumes the representations learned by the HGNN and learns the final user and audiobook vectors jointly, in a common space.
Figure 1B illustrates the construction of the co-listening graph, out of a user-streamings graph which is shown in Figure 1A. The graph structure allows for learning "multi-hop" patterns; that is, if Audiobook A1 is connected to podcast P1 (1-hop relation), and podcast P1 is connected to Audiobook A4, then the implication is that Audiobook A1 and Audiobook A4 are somehow related (2-hop relation). This is illustrated in Figure 2A, along with our previous explanation regarding LLM-derived node features. Once such multi-hop relations are learned, they can be leveraged for making recommendations, even in the absence of Audiobook interaction data. As shown in Figure 1C, the system can then predict the likelihood of a user listening to an Audiobook. This works because the system distills the graph content and interaction signals into user and audiobook/podcast representations. Essentially, representations are sequences of numbers, such that a user representation Repr(U1) that is similar to an audiobook representation Repr(A2) means that user U1 will likely enjoy Audiobook A2.
But how do we turn a graph signal into a set of representations for each user and each Audiobook / podcast? We employ a novel combination of Heterogeneous Graph Neural Networks (HGNNs) and a two-tower model (2T).
Graph neural network. The HGNN operates on the established paradigm of message-passing: initial representations for each node are “communicated” through aggregation functions to their nearby nodes and then gradient learning updates each representation according to the “messages” communicated by its own neighbors. This is repeated for multiple epochs to obtain final Audiobook/Podcast representations, as is illustrated in Figure 2A.
Two-tower model. The HGNN representations are then fed into a 2T model which accounts for additional user signals, such as demographics. This is also the component which accounts for the users’ music preferences. Overall, the 2T model associates user and audiobook vectors, so they can be compared in the same mathematical space. We also employ weak signals, such as previewing or following an Audiobook.
Combining the HGNN with the lightweight 2T model also allows for scalability, because it means that we can implement the user-specific side of modeling outside of the HGNN. Therefore, the HGNN is trained on the co-listening graph (Figure 1B) rather than the user-streaming graph (Figure 1A) containing a massive amount of individual user-content interactions.
After successfully testing our model in offline data, we performed an A/B test involving millions of users. The online test resulted in a significant 23% increase in audiobook stream rates. Remarkably, we observed a 46% surge in the rate of people starting new audiobooks. The model is since then in production, exposed to all eligible audiobooks Spotify users.
A unified model for personalization
In our second paper presented in the Web Conference, in the Graph Foundation Models workshop, we take the so far discussed idea one step further. We are motivated by the fact that representations for Audiobooks and Podcasts are already learned jointly within the Graph Neural Network. These representations are generic enough that can be seen as a foundation layer, that is, a general, domain-agnostic representation that can be adapted to serve different downstream tasks. Further, this foundation layer is static, in the sense that it only needs to be updated infrequently due to the relatively slow changing catalog of podcasts/audiobooks. To enable the foundational representations to be used in a variety of tasks, we re-purpose the previously discussed 2T model to become an adaptation mechanism. Specifically, the Audiobook tower of Figure 2B now becomes a general "item" tower, which is content type agnostic and can handle Audiobooks, Podcast shows and Podcast episodes in a Unified Way. This constitutes a dynamic layer, because it is lightweight and user-specific, so it can be updated frequently and at a low cost.
As discussed above, the Unified Model architecture decouples the content representation learning (static layer) from the user representation learning (dynamic layer). The benefit of such an approach is that it unifies representation learning across various tasks, it enables information sharing, improves the quality of learned representations, and simplifies production pipelines. Furthermore, it is an efficient way to deal with the challenge of representing new episodes while avoiding bias towards recency and being responsive to user interactions in near real time.
The Unified Model provided quantitative gains in offline experiments, such as a 16.6% increase in the HR@10 metric for audiobook recommendations, against an Audiobook-specific model. Besides, our offline results also showed almost identical performance of the model versus a variant which is re-trained daily. This confirms that the HGNN foundation representation remains stable over time and can be effectively utilized in the Unified 2T model on a daily basis without the need for frequent retraining. Since the publication of our workshop paper we have also conducted an A/B test which demonstrated that the Unified Model also provides gains in the online setting.
Conclusions
We leveraged the power of graph-based learning to personalize audiobook recommendations in Spotify. Our modular approach allows us to decouple complex item-item relationships while producing scalable recommendations for all users. In subsequent work we equipped the model with foundational modeling capabilities. The resulting representations can be used for multiple downstream tasks related to the personalization of multiple content types, including podcasts. We consider this to be a step towards the first graph-based, foundation model tailored to the domain of personalization. We believe that this work showcases the promise of graph-based foundation models in industrial applications.
For more information please refer to our papers:
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks. Marco De Nadai, Francesco Fabbri, Paul Gigioli, Alice Wang, Ang Li, Fabrizio Silvestri, Laura Kim, Shawn Lin, Vladan Radosavljevic, Sandeep Ghael, David Nyhan, Hugues Bouchard, Mounia Lalmas-Roelleke, Andreas Damianou The Web Conference, 2024 (Industry Track)
Towards Graph Foundation Models for Personalization. Andreas Damianou, Francesco Fabbri, Paul Gigioli, Marco De Nadai, Alice Wang, Enrico Palumbo, Mounia Lalmas The Web Conference, 2024 (Graph Foundation Models Workshop)
SHARE THIS ARTICLE

