Giving Voice to Silent Data: Designing with Personal Music Listening History
“Silent” data shapes our listening experiences
To drive personalization and help listeners discover music, Spotify and other music streaming services collect all kinds of data about users’ listening habits—which songs they play most, with whom they share them, and what time of day they listen. This data typically shapes the listening experience from behind the scenes: it’s used to make recommendations for what the listener might want to hear based on their previous habits, but the data itself is not surfaced to the listener as each track is selected. This is especially true when listening is happening on voice-activated devices, where ephemeral interactions provide less context for users.
This is what we refer to as silent data: Information that drives the listening experience, but is not surfaced to listeners directly.. To explore how to make silent data meaningful to music listeners, we conducted design workshops with 10 Spotify listeners to assess how listeners might imagine new ways of interacting with their personal listening history data in the context of using a voice assistant.
Our research process: Design workshops using personal music listening data as a material
We conducted an empirical study consisting of workshops where we asked participants to design potential future interactions with a voice assistant around music. This approach draws on the tradition of research through design, where design practices are used to generate knowledge about how people interact with technology.
We recruited 10 highly active Spotify listeners who regularly use voice assistants and self-track personal data in some way, like keeping a journal or wearing a smartwatch. We focused on these extreme users in order to push beyond current listening and voice paradigms. As a prompt, we gave each participant a customized data profile, generated from their Spotify listening history, that included top most-played songs, temporal patterns, and genre preferences.
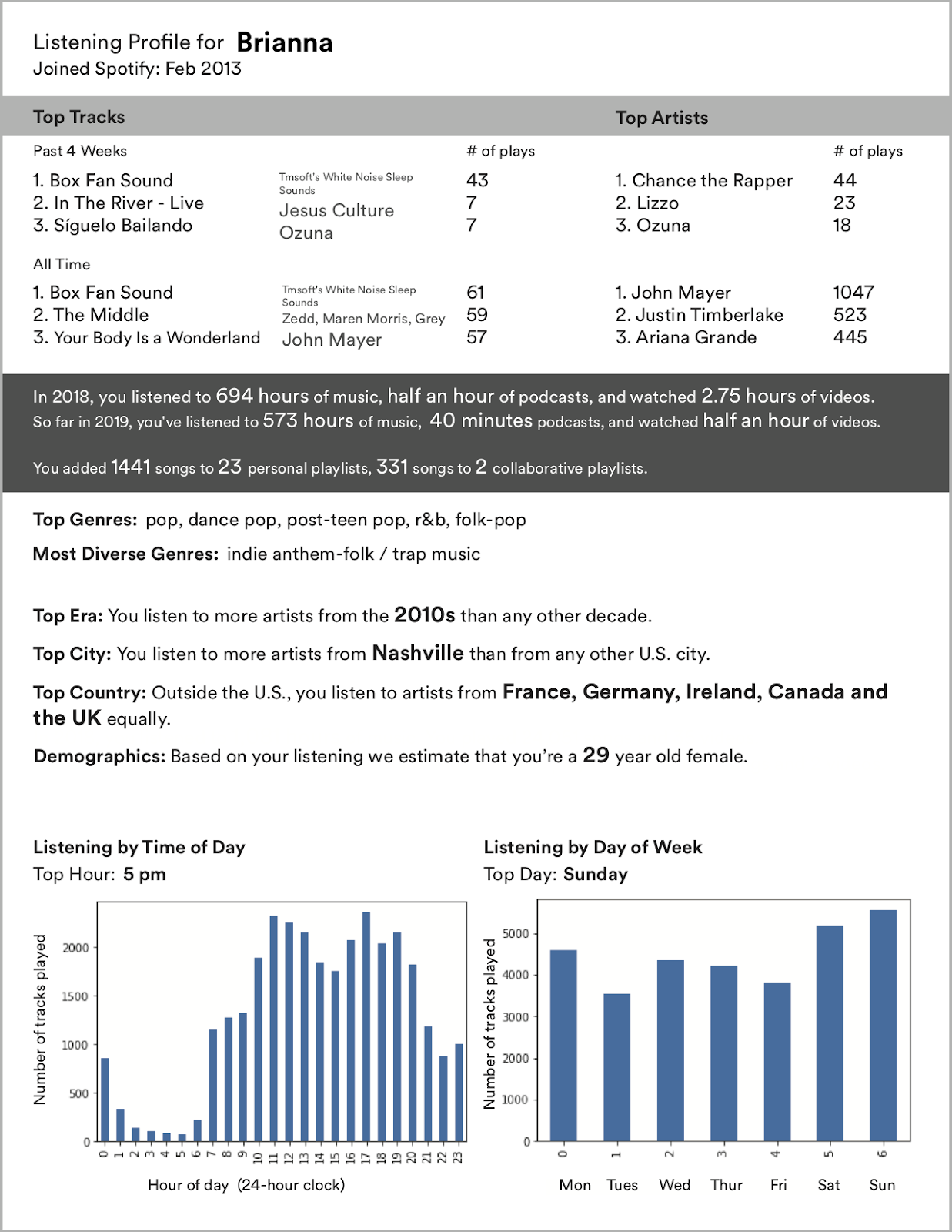
This is an example of a personal data profile for one of our participants that we created from data about their Spotify account. It included information like top songs (of the past month and all time), top genres, how many playlists they created, and what time of day and week they listen to Spotify.
We conducted the workshops in pairs (five workshops total) so that participants could interpret their personal data in a social context and bounce ideas off each other. The workshops included a range of design activities that encouraged participants to reflect on their data in diverse ways:
A guided visualization exercise imagining a hypothetical interaction with one of their most-played songs and a voice assistant
Mapping out conversational voice interactions with structured dialog cards
Exchanging data profiles and discussing them
Building a timeline of voice interactions unfolding over the course of someone’s life.
Interacting with Wizard of Oz prototypes of their new voice interactions, that incorporated text-to-speech, music, and sound effects.
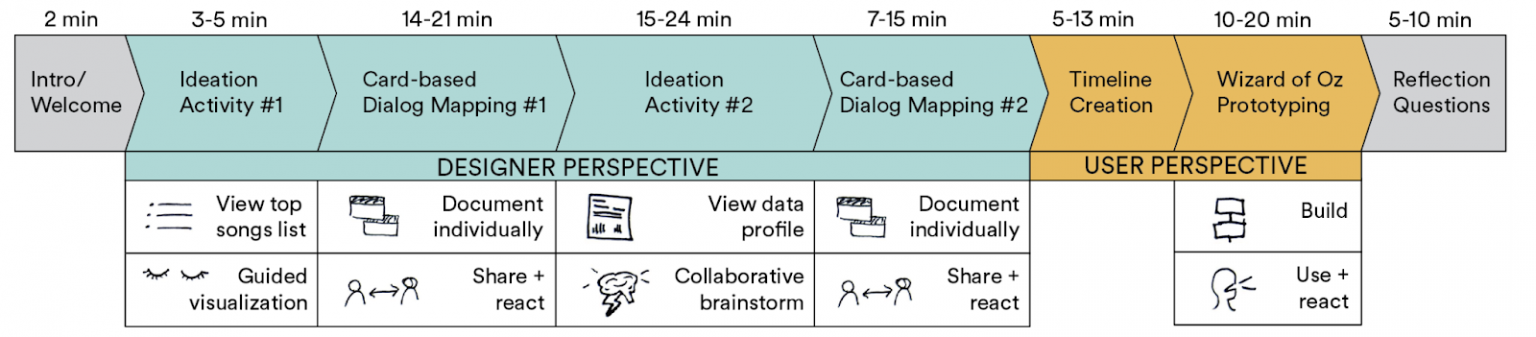
An overview of the design workshops structure, which started with activities that encourage participants to take a designer perspective and finished with activities that encourage them to take a user perspective. A full study protocol is available in our supplemental materials in the ACM digital library .
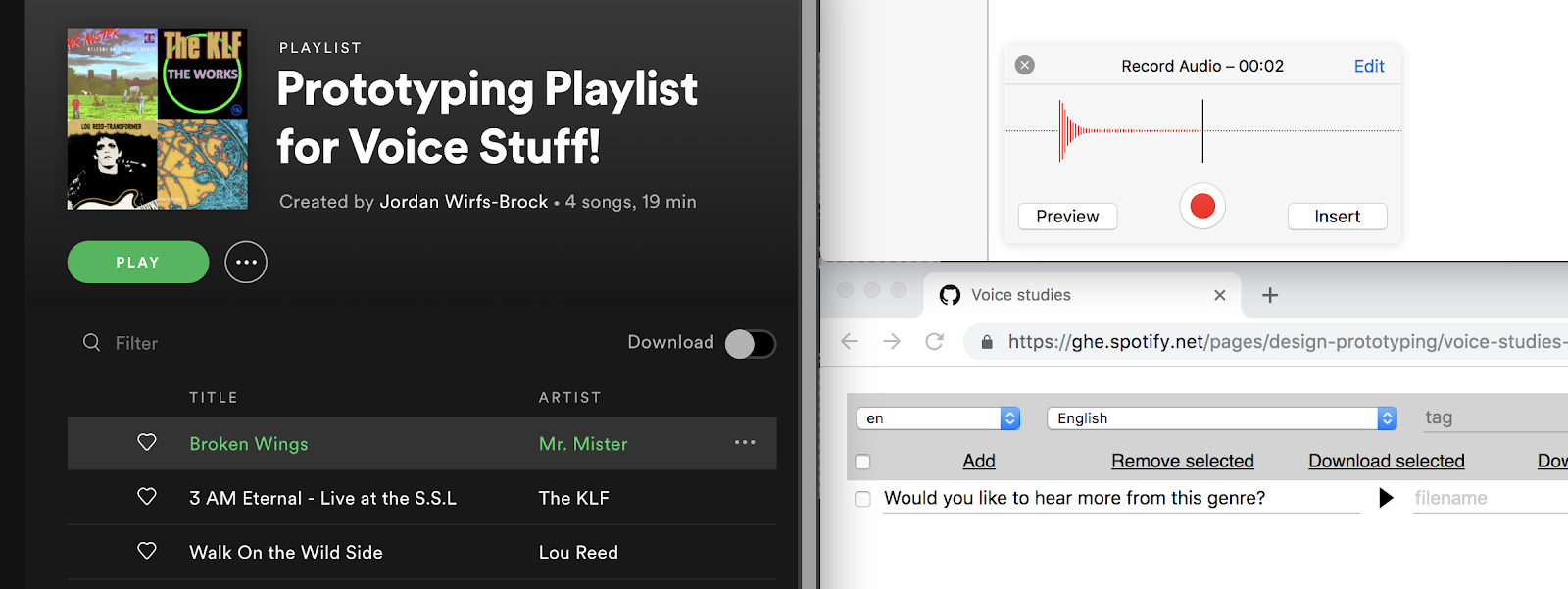
A screenshot of our Wizard of Oz prototyping environment, which allowed us to queue and play songs, custom-recorded sound effects, and text-to-speech voice responses.
From the workshops, we landed on four key takeaways that emerged about how we might use personal data as a design resource to inspire new voice interactions**.**
Theme 1: Personal data helps people reflect on their identities as listeners
Through viewing their personal listening history data, participants reflected on their identities as music listeners. Sometimes, the data validated pre-existing views participants held – like how they’re a person who has eclectic taste, or is a superfan of an artist. Other times, the data caused participants to change how they thought about themselves.
A data metric can hold many meanings. Take play counts: A song with a lot of plays could indeed be someone’s favorite. Or it could be the music they listen to while they sleep, or their child’s favorite song.
Or, consider the act of listening itself: One participant associated listening with being busy at work. Upon seeing how many hours a week he listens to music, he said that he needs to work less, and “get outside more.” Whereas another participant saw that same metric and commented that he needs to listen to more music – something he associates with downtime.
These reflections on what it means to be a music listener – inspired by the act of looking at and discussing logged listening data – could lead to deeper, more deliberate music listening practices.

Engaging with logged data can lead to reflections on identity and listening practices.
Theme 2: Personal data grounds futuristic thinking in current experiences
As participants interpreted, reflected on, and designed with their data, they grounded their futuristic thinking in their current experiences. For example, one participant reflected on discrepancy between her top songs of the past month and her top songs of all time. She described how she goes through phases where she becomes obsessed with an artist or song and listens nonstop until she gets burnt out and can’t listen anymore. To remedy this, she imagined a voice assistant that could help her manage this behavior and extend the pre-burnout phase:
I wish it was like when I hit five listens in one day, it was like, “You’ve listened five times. Here’s another artist that opened for her.” Or if it gave me other context where I could get distracted from her a little bit.
This futuristic interaction solves a real, everyday problem.

An example of the data in one of the participant’s data profiles and the novel voice experience that reflecting on this data inspired.
We also shared metadata that participants might not have been aware of, such as genres of their favorite artists or their geographic origins. Some participants imagined a voice assistant prompting them with these metadata dimensions, like: “You listen to more artists from Detroit than any other city – would you like to hear a Detroit playlist?” Thus,exposure to this metadata provided a new lens on participants’ existing behaviors, enabling them to imagine new interactions that authentically reflect their current listening practices.
Theme 3: Data can be a trigger for interaction, rather than a focus
Going into this study, we hypothesized that people might want to explore their data using sound and voice as a standalone activity, and would perhaps want something like an voice-mediated version of Spotify’s year-end “Wrapped” feature. Instead, personal data served as a trigger, not a focus, of voice interactions: Participants honed in on data milestones—the 100th song added to a playlist, the anniversary of the first time they heard a song—as events that might trigger a voice assistant to suggest actions, like sharing the playlist, or exploring adjacent music.
These interactions explicitly reference data points, but the data isn’t the point. The point was an enhanced way to meaningfully explore music, using personal data as salient ways to enter these new interactions.
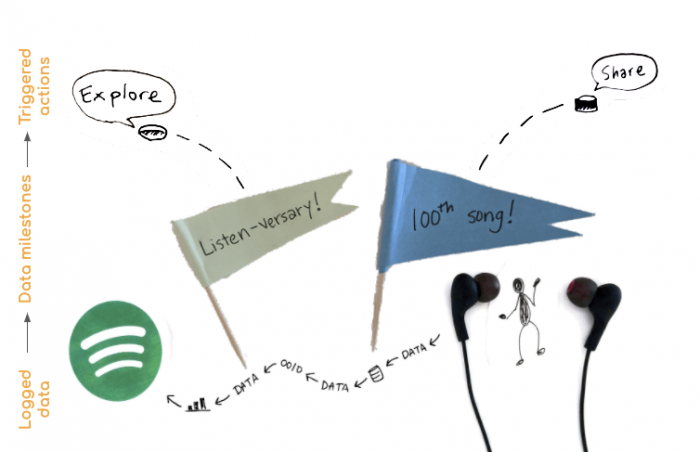
Logged data, like the date a user first listened to a song or the number of songs in their playlists, could become data milestones that trigger voice suggestions for action, such as exploration or sharing.
Theme 4: Data can help us take voice assistants from voice-activated remote controls to personalized music coaches
One of the main ways people use voice assistants and smart speakers is to play music, but they tend to use simple functions, like asking for a song or pausing playback, treating them as glorified voice-activated remote controls. In our workshops, however, we found that participants imagined something less like a voice-activated remote control and more like a music coach who could proactively support them as they expanded their musical personalities and evolved their musical tastes. Participants imagined voice assistants that have musical intelligence, and that leverage to do things like jumping straight to the chorus, reciting back lyrics, or explaining the meaning of a song.
Some participants imagined that this musical intelligence might even be combined with intelligence about them, the listener. But people acknowledged that this might not work right off the bat, and that they’d have to collaborate with the voice assistant and teach it their preferred ways to interact. This process might unfold through errors: Participants didn’t expect a voice assistant will always get things right, but they did hope that it might ask for feedback so it could course-correct when it gets things wrong. Another way participants might teach a voice assistant how they like to interact is through tagging the music with their own language, “I feel like it’d be really easy to be like, ‘I like that...that song makes me feel really happy’ or ‘I’m feeling uplifted.”’
Through this kind of specific, on-the-fly labeling of their music experiences, participants described building a personalized, shared language with the voice assistant. They also imagined dialogs where they could decide, with the voice assistant, what to listen to—collaborating with the voice assistant, as a music coach, to figure out what to play, rather than simply commanding it.
Considering these findings, we leave you a challenge for applying this approach to your research and design work.
Challenge: Turn silent data into a vocabulary for exploration – alongside end-users
We found that presenting people with silent data provided a new lens on their existing behaviors and a new vocabulary for understanding them. This new vocabulary can also scaffold people as they discover features or content. Exposing silent data may be a way to tackle a common problem in voice interaction design: How do users figure out what they can do with voice assistants? Imagine this interaction:
A user asks a voice assistant, “Play more music like this.”
The voice assistant might respond, “Ok, how would you describe this song in your own words?”

Involving end-users in the process of logging and interpreting meta-data could be an inroad into feature discovery in voice interactions.
Or, after playing an algorithmically selected song, a voice assistant could ask users why they think it chose that song, then respond with the reasoning behind the recommendation.
These types of interactions expose and build the system’s contextual intelligence, while also teasing out a user’s preferences. Thus we challenge you to consider additional ways previously silent data might become a new vocabulary for exploration. But in order to use silent data to derive a user-centric vocabulary of exploration, we first have to understand it. One way to do this is to involve end-users in the design of data logging capabilities. Users have valuable knowledge about what data metrics mean that are often unavailable to designers. Data-inspired design activities, with end users, can spark forward-focused, generative discussions about what people can do with their data.
For more on this work, read our CHI 2020 paper or watch a video presentation of our findings.
SHARE THIS ARTICLE