Modeling Users According to Their Slow and Fast-Moving Interests

Music recommendation systems at Spotify are built on models of users and items. They often rely on past user interactions to learn users’ preferences and generate appropriate representations of these preferences. In this paper, which is presented at WSDM 2022, we developed an approach for learning user representations based on their past interactions.
In music recommendation, users’ interests at any time are shaped by the following factors:
General preferences for music listening
Momentary interests in a particular type of music
The first types of interests are mainly slow-moving and may vary gently over time. However, the second types are fast-moving preferences, and represent instantaneous tastes which might change rapidly.
For instance, a casual music listener Bob generally likes Pop and R&B genres and listens to them frequently. Last month, Bob started exploring Jazz music for a couple of days. More recently, he has been exploring Classical music and has found it interesting. Now, a recommender model is trying to understand his music taste to suggest him the perfect music track to listen to. If we look into the bulk of his listening, Pop and R&B music are highlighted. However, we know that more recently he has been exploring music within the Classical genre. How can we best represent user interests at the moment? If we were to recommend a track, should we focus on his all-time favorites Pop and R&B or his momentary interest in the Classical genre? Or both? How would the two interest groups, general and momentary, interact with each other and how should we account for them?
By recognizing these two different components of user interests, we developed an approach for learning user representation based on slow-moving and fast-moving features. Our model is based on a variational autoencoder architecture with sequential and non-sequential components to analyze fast-moving and slow-moving features, respectively. We call the model FS-VAE. We train the model on the next item (track) prediction task.
We evaluated FS-VAE on a dataset consisting of music listening and interactions for users over a 28-day period. Our experiments showed clear improvements over the prediction task compared to state-of-the-art approaches and verified the benefits of our approach on this recommendation task. Our methodology showed numerous advantages:
By defining slow and fast features, we can capture general users’ preferences alongside their instantaneous tastes.
Modeling slow and fast features with non-sequential and sequential components allows us to learn the bulk of user tastes through aggregation at scale while individually analyzing recent fast-moving features for capturing momentary tastes.
The probabilistic nature of our model for user representation learns a function through the inference process for representation rather than point estimates. Variational inference enables us to learn non-linearities in highly complex user behavior and better understand listening patterns.
Data
We work on a streaming dataset consisting of a sample of over 150k users and 3M tracks over a 28-day period. As we focus on learning user representation, we let each track be represented by an 80-dimensional real-valued vector acquired in a pre-processing step via a Word2Vec-based model. This dataset contains the times of each listening event and aggregated users’ interactions with tracks (if any). These are i) total number of likes, ii) total number of tracks added to their playlists, iii) total number of skipped tracks, and finally iv) total number of restarts (restarting a track).
Model
Our model consists of variational encoder and decoder blocks. To capture general and all-time user preferences, we design a regular encoder that takes in aggregates of historical user interactions. A second sequential component in the encoder block takes in fast features individually corresponding to recent user interaction. This enables the model to learn any momentary taste or trends in user preferences. The user representation is then the output of the encoder state, which is taken in by the decoder. We train the model end-to-end on the next track played by the user.
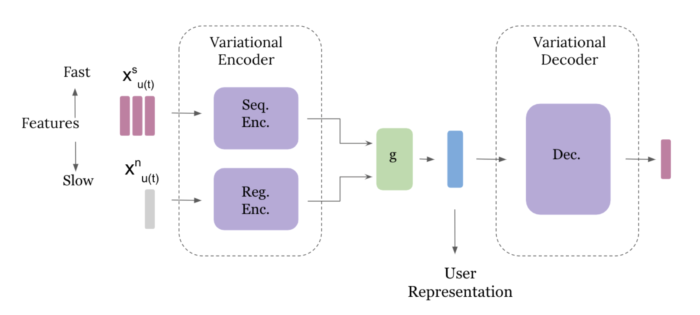
The sequential encoder consists of two LSTM cells with LeakyReLU activation function. The regular encoder and decoders are two-layer feedforward networks with LeakyReLU activations.
Results
To evaluate the performance of our model FS-VAE, we compare with several baselines:
Vanilla RNN: This baseline takes in the sequential features and trains an RNN model to predict the next track played by a user.
Aggregate Sequence: For this baseline, we aggregate the sequential features and feed them along with the slow features to the model.
Popularity: We use popularity to recommend the next tracks to the users.
Average: Since we are training and predicting in the track embedding space, this baseline takes the average of past tracks listened to by a user as the next track prediction.
LatentCross: This RNN-based model combines the sequential features with contextual features into a deep architecture for a recommender system.
JODIE: This model learns the embeddings from sequential and contextual features.
VAE Collaborative Filtering: This is a collaborative filtering baseline that trains a variational autoencoder for recommendation tasks.
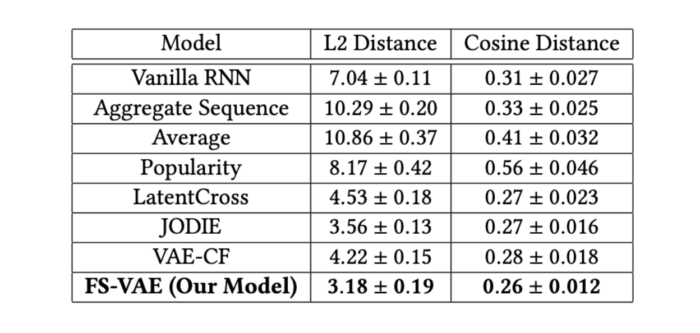
Our metrics are norm-2 distance and cosine distance between the predicted track and ground truth within the 80-dimensional track representation space. Our model resulted in significant improvement in prediction distances for the next track played by the users in a test set compared to other baselines.
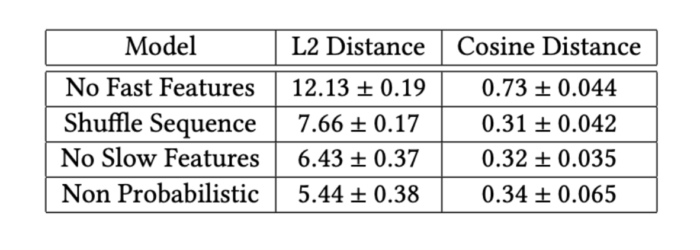
To further investigate fast and slow-moving features as well as our model components, we ran ablation studies. We analyzed the results with i) no fast features, ii) no slow features, iii) non-probabilistic architecture (optimizing for maximum likelihood instead of the variational objective), and finally, iv) shuffling sequential features. The last one could be an indicator of whether there is any valuable information in the order with which tracks appear in sequences consumed by users. As noted in the following table, we observe that the prediction errors increase certifying the crucial role each feature and component plays.
Summary
In music streaming applications, users’ preferences at any given moment are influenced by their general interests as well as their instantaneous tastes. Our goal is to learn these factors and capture them in users’ embeddings from the slow-moving and fast-moving features, respectively. We develop a variational autoencoder model that distinctively processes slow-moving and fast-moving input features in non-sequential and sequential model components respectively. Our experimental results on the next track prediction task on a Spotify streaming dataset show clear improvements over the current baselines.
More information can be found in our paper: Variational User Modeling with Slow and Fast Features Ghazal Fazelnia, Eric Simon, Ian Anderson, Ben Carterette, & Mounia Lalmas. WSDM 2022.
SHARE THIS ARTICLE

