Exploiting Sequential Music Preferences via Optimisation-Based Sequencing
We study the problem of constructing personalized playlists for users of music streaming services, in our case Spotify. To deliver best in class experience for such users not only understanding the users’ preferences over individual music tracks but also understanding how users consume the tracks as they navigate through playlists is important. In contrast to many other recommendation domains (such as movies or books) consumption of music is inherently sequential: users rarely listen to only a single track from a playlist; instead, they typically consume the entire sessions, or sequences of tracks, one after another. In our work we examine the sequential music preferences of users and look at how we can leverage such sequential preferences in an optimisation-based way.
We show that even simple ML models are capable of capturing the most essential sequential aspects of users’ preferences. Through extensive offline off-policy evaluation, we demonstrate how our optimisation-based sequencing approach can leverage such ML models to increase consumption. Finally, relying on a large-scale A/B test we show that we can significantly increase the number of completed tracks in users’ sessions.
Sequential Music Preferences
Generally, there exist numerous different aspects of users’ sequential preferences. Consumption of any track by the user may be affected by the user’s past short-term and long-term consumption in many ways; it may further depend on the user’s expected future consumption, etc. In our paper, we argue that while capturing more of such sequential aspects is possible by building more complex ML-based preference models, the problem of constructing optimal playlists by employing such models becomes computationally intractable.
Therefore, instead of trying to capture all the subtle aspects of the users’ sequential behavior, we only identify two basic sequential hypotheses that most of the users’ preferences would have. We then try to leverage these specific hypotheses in the sequencer in an optimisation-based way.
To this end, we first posit that there exists a relationship between users’ consumption choices and the positions of the tracks in the playlists. Intuitively, the first track in the playlist may be indicative for the user to decide whether they would like to start listening to the playlists. As an example, if the track on the first position is familiar to the user, the user starts consuming tracks from the playlist maybe more likely. As a second example, if the user has reached the further positioned tracks, the user continuing consuming tracks from the playlist is more probable. We refer to such preferences as position-aware preferences.
Second, we hypothesize that whether the user consumes a track on a certain position depends not only on that specific track but also on the track on the previous position. Intuitively, if the adjacent tracks are significantly different in their acoustic features, the resulting music flow may become less coherent and consequently, less enjoyable for the user. Figure 1 illustrates the acoustic energy of the tracks on positions 2 and 3 of the playlist. We can see that if the acoustic energy of the respective tracks is more similar (blue line), it makes it more likely that the user completes both tracks. However, as the difference in the acoustic energy gets larger (red line), the user would more likely skip the latter track. In what follows, we refer to such preferences as local-sequential preferences.
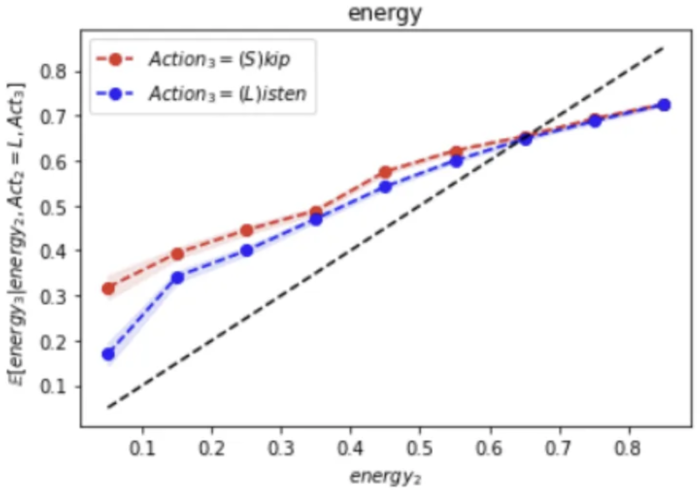
Figure 1. Mean acoustic energy of two adjacent tracks. Track on position 2 is completed by the user. If the acoustic energy of the tracks is similar, it is more likely that the track on position 3 is completed (blue); otherwise, it is likely that track 3 is skipped (red).
Optimisation-Based Sequencing
We frame the playlist sequencing problem as a stochastic optimization problem. We model the rewards r of the user interacting with the music tracks as random variables. These rewards may depend on the user u, the track t as well as on the entire sequence of tracks π (see Figure 2). In this case, we aim at finding such a sequence of tracks π that maximizes the expected total discounted reward. Equation 1 illustrates our approach.
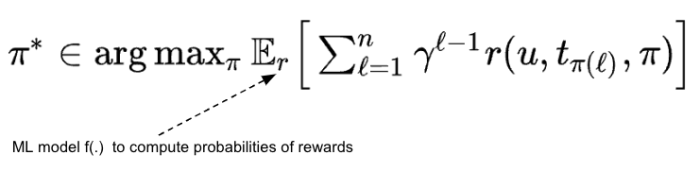
Equation 1. Optimal Sequencing Problem
Such a generic formulation allows us to explicitly introduce our position-aware and local-sequential assumptions into the ML-based preference model f(.) that predicts the probabilities of the different rewards r. In our paper, we illustrate how this can be achieved with fairly simple ML models. The resulting probabilities estimated by such models allow us to solve the sequencing problem in an optimisation-based way.
Experiments
To better understand whether introducing the position-aware and local-sequential assumptions into the preference model allows to increase consumption we rely on offline off-policy evaluation. To this end, we first ran a randomized data collection A/B test when we exposed the users to the playlists ranked with a uniform random logging policy. We then relied on the collected randomized data and on inverse propensity scoring (IPS@k) to estimate the expected number of completed tracks across the first k positions of the target policies defined by our optimal sequencing problem (see Equation 1). We relied on two modifications of IPS, namely Independent IPS (IIPS@k) and Reward-Interaction IPS (RIPS@k) that allows us to explicitly model the sequential rewards.

Table 1 illustrates the estimated expected numbers of completed tracks across the first k positions. Introducing the position-aware and the local-sequential assumptions into the preference model helped increasing the expected number of completed tracks compared to the simple relevance sequencer (i.e, a simple model that ranks tracks using the cosine similarity between the user/track latent representations) as well as to the state-of-art neural non-sequential Myopic sequencer.
When looking into the acoustic coherence of the playlists constructed with our local-sequential model we also observed that our model allocates acoustically similar tracks closer to each other compared to the non-sequential Myopic sequencer. Figure 2 illustrates the difference in acoustic features between the two adjacent tracks for the first nine positions of the playlist. We see that the acoustic difference for the sequential model (blue) is typically smaller than for the non-sequential one (red) for all twelve acoustic features. This suggests that our sequential model can help to construct playlists that deliver a more acoustically coherent music flow to the users compared to the non-sequential models.
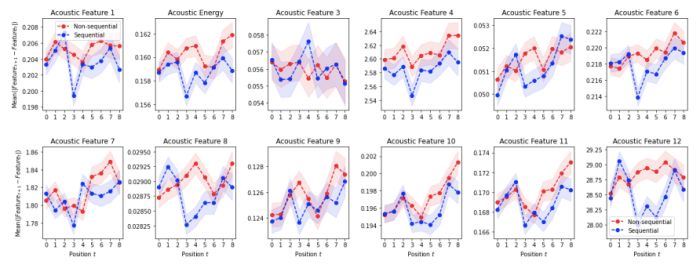
Figure 2. Mean distance between the acoustic features of consecutive tracks across different positions of the playlists.
Finally, we relied on our best-performing local-sequential model to carry out an online A/B experiment. We saw that our model allows us to increase the number of completed tracks per session by +2.52% relative to the non-sequential baseline. Skip rates decreased by -2.73%.
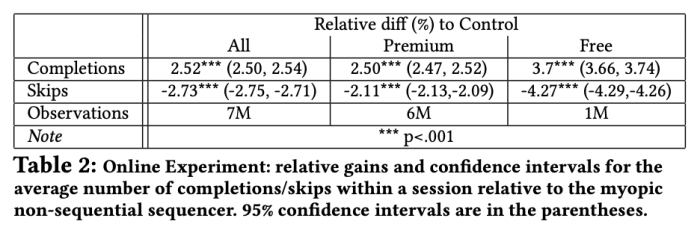
These results are even more pronounced for Free users than for Premium ones. This allows us to significantly improve the experience of free users who can only skip a limited number of tracks. Table 2 illustrates our results.
In conclusion, we see that relying on sequential models and optimisation-based sequencing allows us to significantly increase the number of completed tracks in users’ sessions and decrease skips. We also see that the resulting playlists are more acoustically coherent.
For more information, please refer to our paper: Exploiting Sequential Music Preferences via Optimisation-Based Sequencing Dmitrii Moor, Yi Yuan, Rishabh Mehrotra, Zhenwen Dai, Mounia Lalmas CIKM 2023
SHARE THIS ARTICLE
