Deriving User- and Content-specific Rewards for Contextual Bandits
Given the overwhelming choices faced by users on what to watch, read and listen to online, recommender systems play a pivotal role in helping users navigate the myriad of choices. Most modern recommender systems are powered by interactive machine learning algorithms, which learn to adapt their recommendations by estimating a model of the user satisfaction metric from the users feedback. Bandit algorithms have gained increased attention in recommender systems, as they provide effective and scalable recommendations. These algorithms use reward functions, usually based on a numeric variable such as click-through rates, as the basis for optimization.
A proper reward function should correlate well with user satisfaction, to allow the model to learn to serve good recommendations. Most prior work on quantifying satisfaction has relied on leveraging implicit signals derived from user interactions, mostly clicks. Often, click based signals are not informative enough and fail to differentiate between satisfying and dissatisfying experiences of users. Consequently, there has been a pressing need to move beyond clicks and investigate post-click behavior of users. These focus on the engagement of users with the served recommendations and have shown promising results in other areas.
On Spotify, a contextual bandit algorithm is used to decide which content (playlists in our case) to recommend to users. Quantifying such a notion of satisfaction from implicit signals involves understanding the diverse needs of users and their expectations of what is a successful streaming session. Such needs often include how users feel, and the expectations that music recommended to them align with their mood or their intent of the moment. To fulfill these, music streaming services provide users with curated playlists, ranging from ''sleep" to ''run". In addition, and to account for the diverse user interests and plethora of musics, genre playlists have been made available to users, ranging from rap, pop, jazz, to niche ones. As a result, millions of playlists are available to users to listen to based on their intent and needs. Given such a heterogeneity in user needs, and the different intents of content (playlists in our case), it becomes important to consider both user and content behavior to formalize the notion of satisfaction, and in turn design the appropriate reward models to capture these.
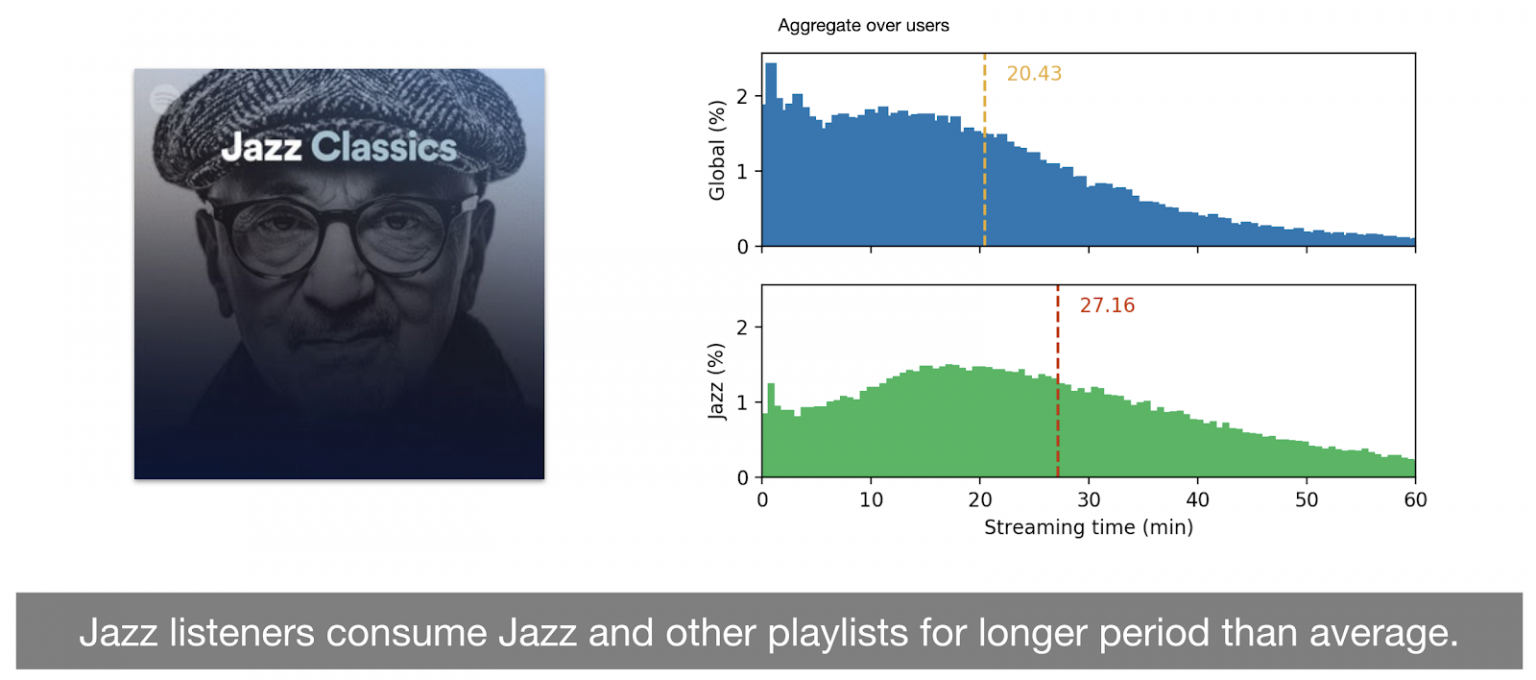
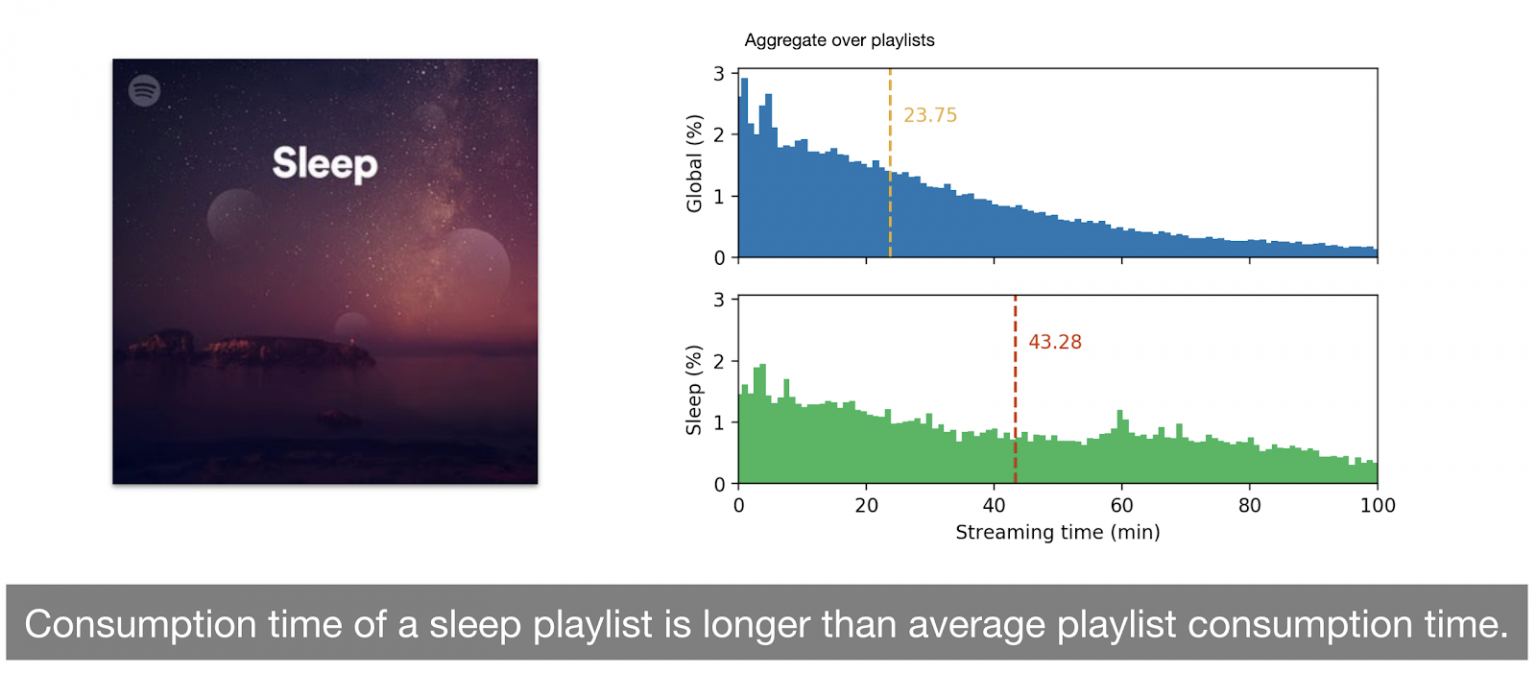
Indeed, a study comparing streaming time distributions associated with specific groups of playlists and users to the global distribution (for playlists and users, respectively) highlighted these differences. For instance, the average streaming time across all playlists is 23.75 minutes, compared to 43.28 minutes for ``sleep'' playlists, i.e. playlists people listen to fall asleep. This is almost double the global average, demonstrating that this type of playlists is listened to in a drastically different way. Now focusing on user types, users who like Jazz music tend to listen to recommended playlists (all playlists, not just Jazz playlists) for longer than other users, with an average of 27.16 minutes, which is significantly higher than the global average of 20.43 minutes. This highlights differences between listening habits of users, as well as different attitudes towards certain types of playlists. This suggests that a reward signal based on a single aka “static'” threshold is essentially averaging-out these peculiarities that are key to better generalization over a vastly diverse set of users and contents. For this reason, we propose an approach to take into account user- and content-specific patterns.
A major portion of work done on specifying reward functions rely on manually crafted functions, including rewards based on click-through behavior of users and other positive and negative feedback signals. Some efforts have looked at strategies to improve the reward estimation in dynamic recommendation environments. Overall, most bandit models powering recommendation systems employ a rather simple threshold based reward function, mostly determined through click-through behavior of the user: if a user clicks on X, a payout of 1 is incurred and 0 otherwise. We go beyond such simple threshold-based formulation, and revisit how success is quantified, based on how users consume playlists and how playlists are consumed by users. We aim at improving upon a current bandit algorithm used to select which playlists to display to users on the home of Spotify. We explore alternative methods to provide a more informed reward function that goes beyond success defined as: 1 if the user streamed and 0 otherwise. These alternative methods are based on the assumptions that streaming time distribution heavily depends on the type of user and the type of content being streamed.
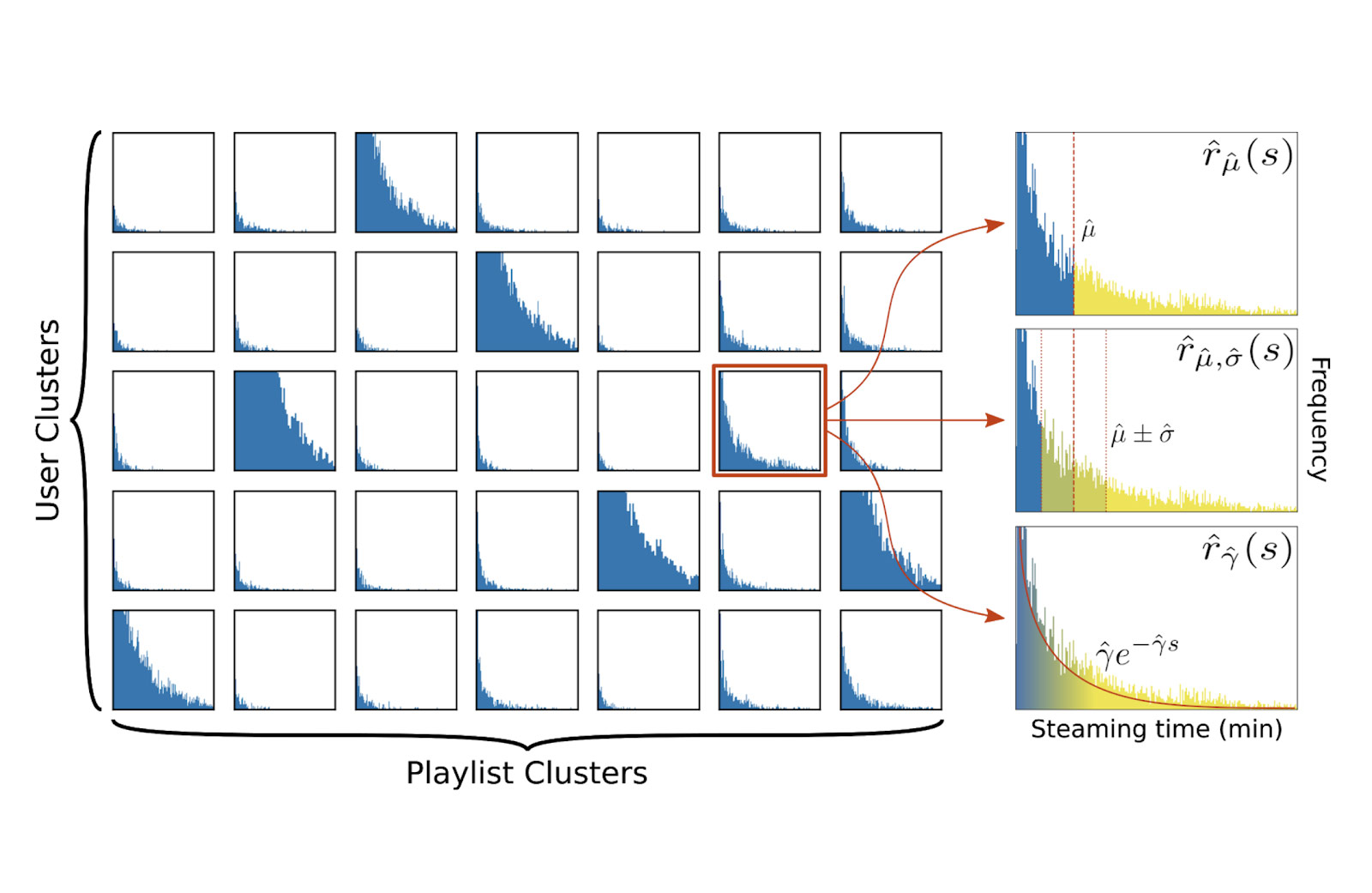
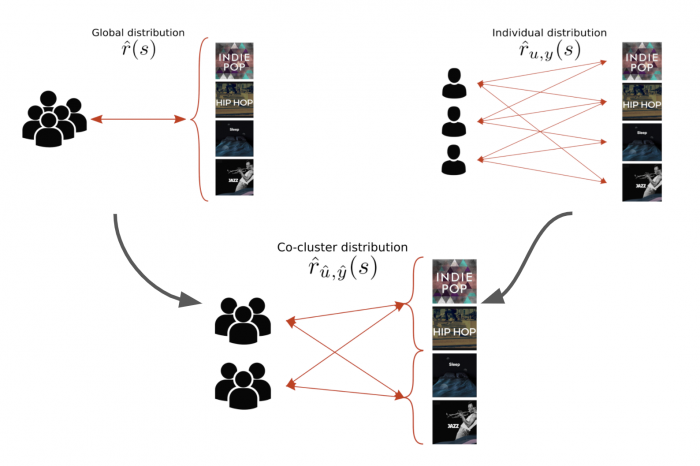
To automatically extract user and content groups from streaming data, we employ "co-clustering", an unsupervised learning technique to simultaneously extract clusters of rows and columns from a co-occurrence matrix.
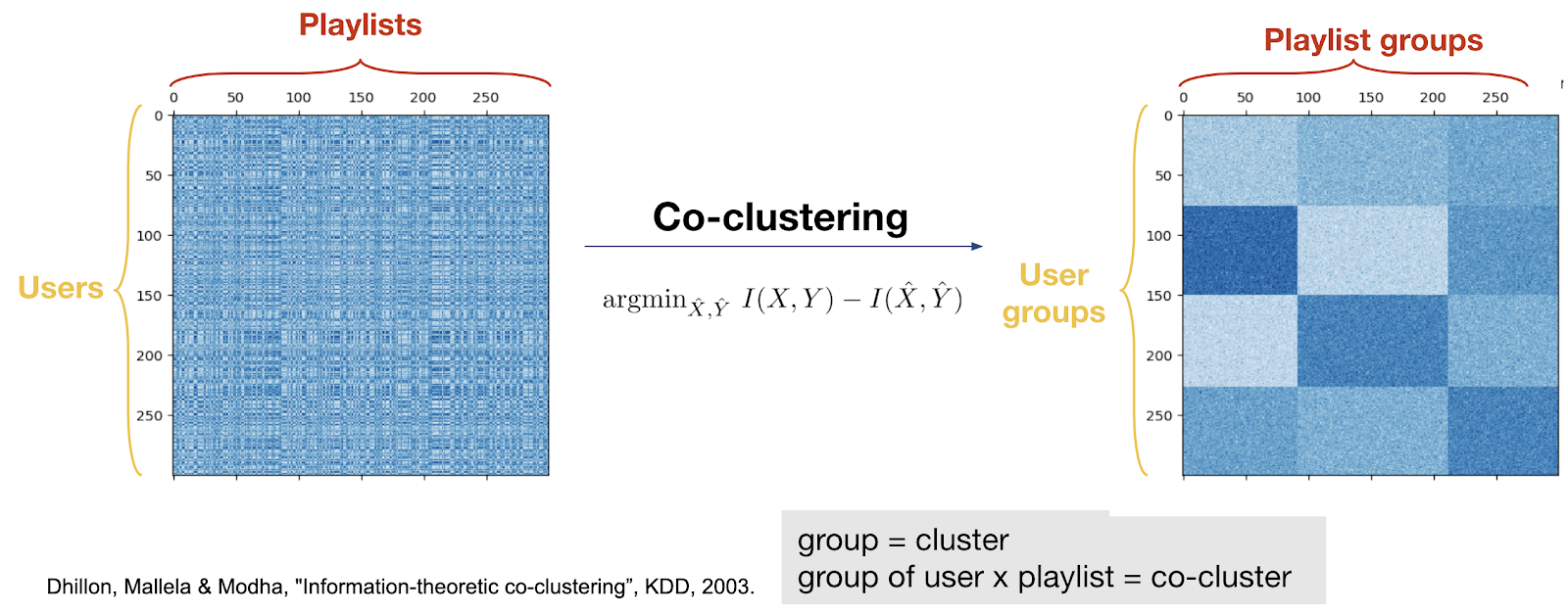
The streaming distributions within the co-clusters are then used to define rewards specific to each co-cluster. Our approach moves from a simple user- and content-agnostic, binary reward model to a more sophisticated reward model, which is aware of the distribution of listening behavior.
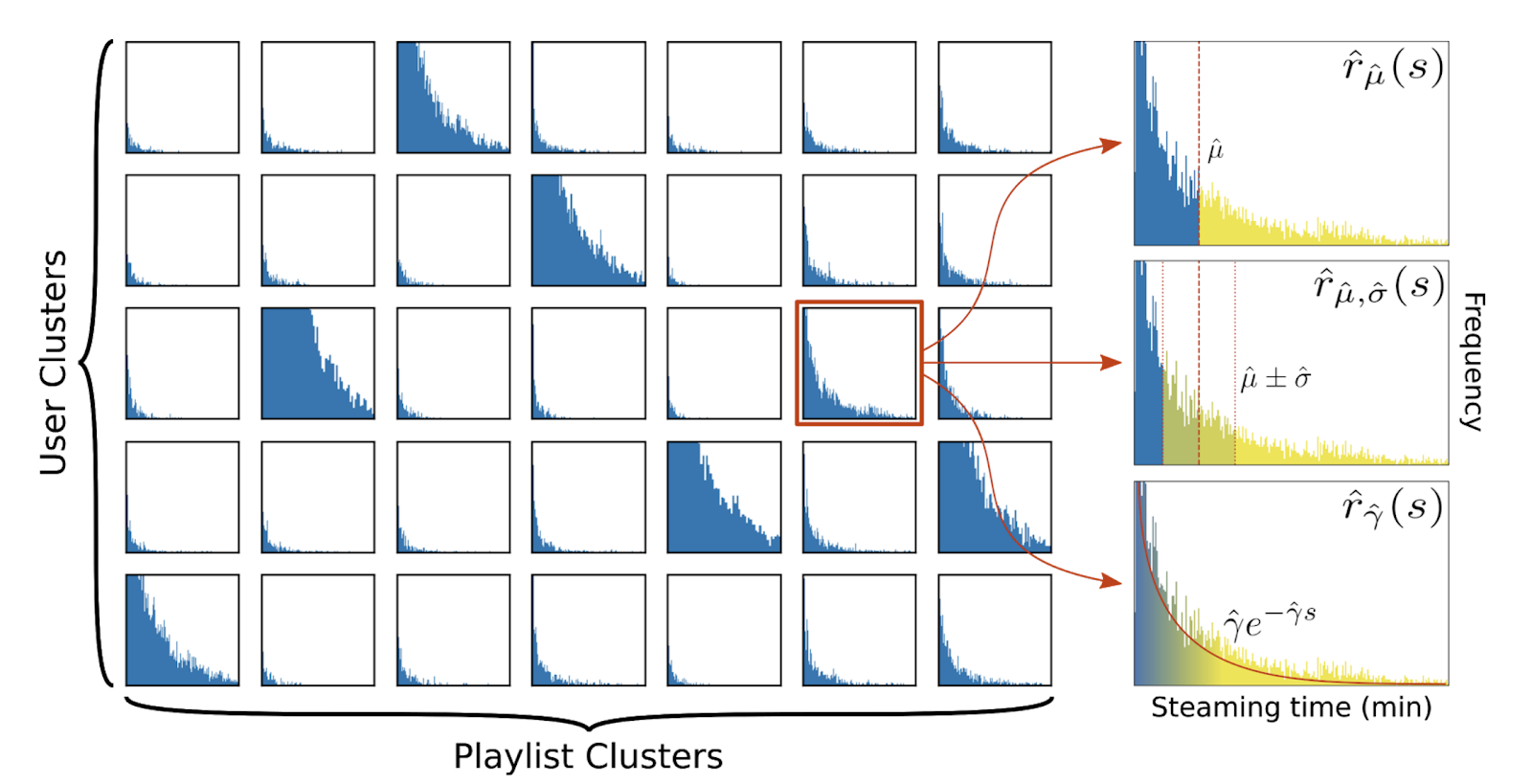
We highlight the need for jointly considering user and content interaction to define rewards, and leverage insights from co-clustering of users and contents together to define rewards. We obtain a substantial improvement of over 25% in expected stream rate with our proposed co-clustering-based calculation of the reward functions.
Further details can be found on our Web Conf paper
SHARE THIS ARTICLE

